论文信息
信息概览
ECCV 2024
论文题目: DoughNet: A Visual Predictive Model for Topological Manipulation of Deformable Objects
论文单位: Columbia University
是否开源: 是
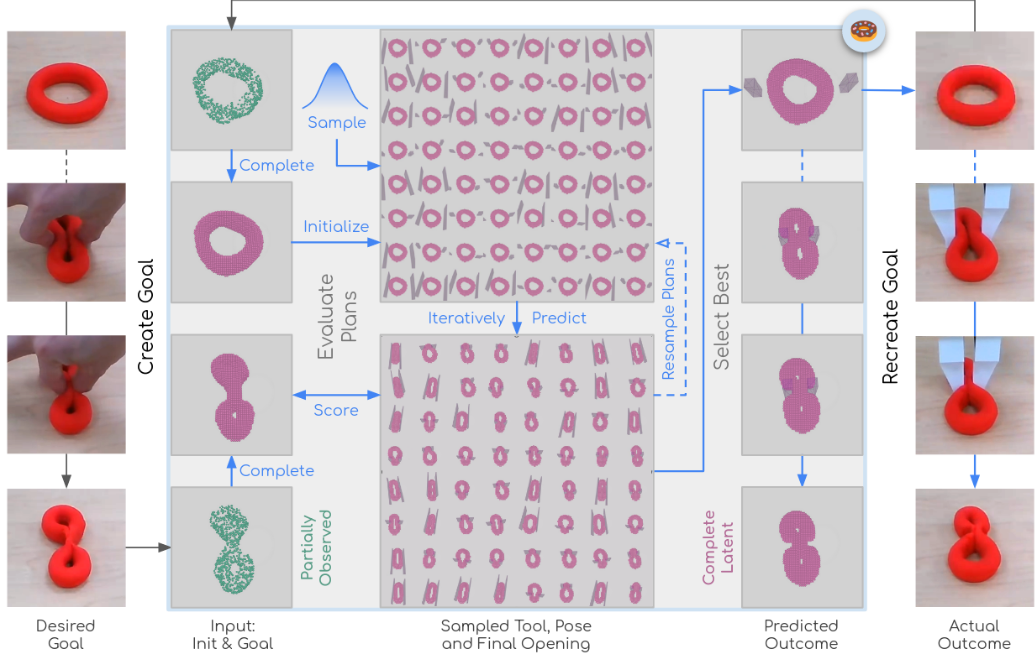
总结: 纯视觉的预测模型,主要用于长时间预测可变性物体(如黏土/橡皮泥)的在不同物理条件下的几何拓扑变换。 可变形物体(如面团)的操作通常涉及拓扑变化(如分裂、合并)。传统方法主要关注几何形变,而忽略了拓扑变化。为了解决这个问题,研究者提出 DoughNet,一个基于 Transformer 的视觉预测模型,能够推测因不同工具或操作方式导致的拓扑变化。
论文细节
输入输出
DoughNet 需要三个主要输入:
初始状态的 RGB-D 图像:通过深度相机(如RealSense)获取点云数据。 由于是单视角,数据是不完整的,因此需要进一步补全。
机器人端执行工具(End-Effector, EE)的几何形状: EE 可以是剪刀、夹子、滚轴等工具,每种工具会对物体施加不同影响。 该工具的几何形状以点云形式输入。
操作轨迹(Action Trajectory):机器人执行的操作,包括工具的移动路径、开合角度、力的大小等。
DoughNet通过潜在空间预测生成两个核心输出:
1 几何预测(Geometrical Prediction):
预测物体的形状变化(如被拉长、压扁、弯曲等)。 结果以点云、体素或隐式表面表示(Occupancy Map) 输出。
2 拓扑预测(Topological Prediction):
预测物体是否会合并、分裂或变形为不同拓扑结构(如从球变为环)。 结果以拓扑图(Topology Graph)形式表示,包括:连通组件数量(Number of Components),每个组件的拓扑属性(如 genus, 环数)。 这些输出最终用于机器人操作规划,帮助选择合适的工具和动作策略。
for example,输入:初始面团形态(RGB-D 图像);给定机器人工具为刀片;再给一段向下切割的轨迹。 那么这个网络会预测切割过程中的形态变化(面团从整体到分裂)及最终分裂后的面团形态(两个独立部分)
网络信息流
编码
DoughNet采用去噪自编码器来处理输入数据,并生成潜在表示(Latent Codes)。
首先对于物体的初始点云数据 $X \in ℝ^{N×(3+1)}$(XYZ 位置 + 深度值)。使用Transformer Cross-Attention 计算点云之间的关系,并生成一组潜在特征(Latent Codes)。 再使用自注意力机制(Self-Attention)在点云上执行全局聚合,生成一个紧凑的潜在编码(Z)。这个潜在编码允许 DoughNet 处理不同大小和拓扑结构的物体。
然后把EE(工具)的几何信息也被编码成潜在向量,与物体的潜在表示一起处理,以推测它们的交互方式。
输出:一组潜在编码 [z],表示物体当前的形状及拓扑信息。
预测
DoughNet采用自回归预测来模拟物体在操作过程中的变化。
输入:
物体当前的潜在编码 [zt]。
EE 的编码 [zt_m],代表操作工具的信息。
当前的操作 [a_t](如 EE 移动路径)。
Transformer 预测:
通过Cross-Attention,模型推测物体与 EE 交互后下一步的潜在编码 [z_{t+1}]。 由于预测发生在潜在空间(Latent Space),计算量较低,且模型可以学习更稳定的特征。
多步预测(Multi-Step Prediction):
由于是自回归结构,DoughNet可以递归地预测未来形态(反复输入自己的输出,进行多步预测)。
预测的输出是: 1 下一步物体的潜在编码 [z_{t+1}]。 2 EE 的影响 [z_{t+1}^m](用于判断 EE 选择是否合理)。
解码
DoughNet 需要将预测的潜在编码转换回物体的几何形状和拓扑结构。
形状解码:采用 Transformer 解码层,将潜在编码 [z] 还原成 物体表面的点云或体素网格。
组件分割(Component Segmentation):预测哪些点属于哪个物体组件(如两个面团是否仍然是一个整体,或已经分裂成两部分)。
拓扑预测(Topology Prediction): 预测物体的 拓扑结构(genus, 组件数),比如:是否分裂?是否合并?是否变成一个环? 采用Cross-Attention计算物体在不同时间步的拓扑关系。
最终输出:完整物体的形状(Occupancy Map, Point Cloud, Mesh)和拓扑结构。