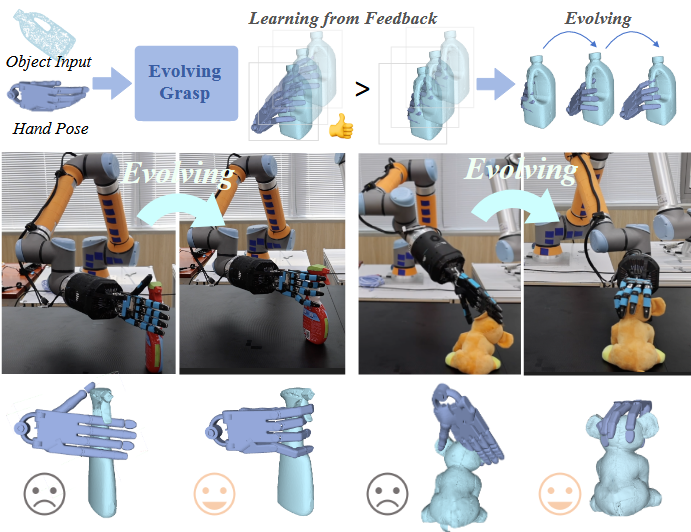
由于在低多样性数据上训练的模型存在局限性,灵巧的机械手通常难以在复杂环境中有效地泛化。然而,现实世界本质上呈现了无限的场景范围,因此无法考虑所有可能的变化.
**现有方法的局限:**传统灵巧抓取方法(优化型或基于学习的方法)依赖有限多样性的数据集,难以适应真实场景中无限的变化。扩散模型虽能生成多样抓取,但存在采样效率低、物理合理性不足的问题
一个自然的解决方案是让机器人从复杂环境中的经验中学习,这种方法类似于进化,系统通过持续反馈进行改进,从失败和成功中学习,并迭代以实现最佳性能。 也就是在动态环境中实现抓取策略的持续优化,同时平衡效率与物理可行性。
问题定义
输入:物体点云 $O\in\mathbb{R}^{N\times3}$ ,表示物体的几何形状。
输出:灵巧手的抓取姿态参数 x
方法
对于一个物体点云O,模型会通过预测噪声,然后去噪得到多个手部姿态的样本。这个样本里有正样本和负样本(判断正负样本的方式是在仿真加扰动,有一些metrics去判断,也可以由人来选择)。然后根据HPO的损失函数来调整模型参数(如LoRA微调),使未来生成的姿态更偏向成功分布,而非直接修改去噪步骤的参数。
HPO
Handpose-wise Preference Optimization (HPO) 基于偏好对齐的进化式抓取生成
目标:通过对比正样本(成功抓取)和负样本(失败抓取)的差异,优化模型生成抓取姿态的后验概率分布。
使用Bradley-Terry模型定义偏好概率: $p_\mathrm{BT}(x_0^w\succ x_0^l)=\sigma(r(x_0^w)-r(x_0^l))$
HPO损失函数:
$\mathcal{L}_{\mathrm{HPO}}=\mathbb{E}\log\sigma\left(\sum_{i=1}^{N_{\mathrm{suc}}}\log\frac{\pi_\theta(x_{n-1}^i|x_n^i)}{\pi_{\mathrm{ref}}(x_{n-1}^i|x_n^i)}-\sum_{j=1}^{N_{\mathrm{fail}}}\log\frac{\pi_\theta(x_{n-1}^j|x_n^j)}{\pi_{\mathrm{ref}}(x_{n-1}^j|x_n^j)}\right)$
通过正样本(成功抓取)和负样本(失败抓取)的对数概率比优化策略,使模型偏好高质量抓取。
Bradley-Terry模型
Bradley-Terry模型是一种用于配对比较(Pairwise Comparison)的概率模型,最初用于预测竞技比赛中选手的胜负概率。
每个选项(如选手或抓取姿态)有一个隐式“强度值”(即奖励函数值 r(x))。
Example: 选手A的强度值 r(A)=2,选手B的强度值 r(B)=1 根据Bradley-Terry模型,A战胜B的概率为 $\frac{e^2}{e^2+e^1}\approx73\%$
在论文中,抓取姿态的“强度值”由隐式奖励函数 r(x) 表示(显式的奖励函数,如“接触点数越多越好”),代表抓取姿态的质量(如稳定性、防穿透性),那么偏好概率公式由以下方程表示:
$p_{\mathrm{BT}}(x^w\succ x^l)=\sigma(r(x^w)-r(x^l))=\frac{1}{1+e^{-(r(x^w)-r(x^l))}}$
$x^w$是成功样本,$x^l$是失败样本,如果 $x^w$ 比 $x^l$更优,则 $r(x^w)>r(x^l)$ ,概率趋近于1;反之趋近于0。
PCM
PCM的核心,一是通过一致性模型框架压缩推理步骤,而是引入物理约束。
一致性模型
从预训练的扩散模型(教师模型)中蒸馏出一个轻量级的一致性模型(学生模型),从而将扩散模型的去噪过程(数百步)压缩为极少数步骤(2-8步),直接学习从噪声到干净数据的映射
自洽性
模型在不同时间步(timestep)对同一噪声输入的预测结果指向同一数据点(即去噪后的干净数据)。例如,输入一个噪声样本$x_t$, (对应时间步 t),模型应直接预测出最终去噪结果$x_0$。输入另一个噪声样本$x_{t'}$,对应时间步$t'$,模型预测的$x_0$应与前者的结果一致。
那么自洽性损失的定义如下:
$\mathcal{L}_{\text{consistency}}=\mathbb{E}_{t,t^{\prime}}\left[\|f_\theta(x_t,t)-f_\theta(x_{t^{\prime}},t^{\prime})\|^2\right]$
在训练时,随机采样两个时间步 t 和 t’,并通过数值 ODE 求解器(如 DDIM)生成相邻时间步的噪声样本$x_t$和$x_{t'}$。 模型需预测两者的去噪结果$x_0$,并通过损失函数强制它们的预测一致。
模型蒸馏
教师模型:传统扩散模型需要 100+ 步去噪(如 DDPM),每一步迭代修正噪声。
学生模型(PCM):通过蒸馏(Distillation)将教师模型的多步去噪过程压缩为单步映射(从任意噪声$x_t$直接预测$x_0$)。
教师模型使用大规模抓取数据集(如 DexGraspNet、MultiDex)训练传统的扩散模型。
学生模型在推理时需满足物理可行性(如避免穿透、保持接触稳定性)。为此,在采样过程中引入梯度引导:
$\hat{\mu}_\theta(x_t,t)=\mu_\theta(x_t,t)+\sum_{i=1}^m\gamma_i\nabla_{x_t}\mathcal{L}_{\mathrm{PA}_i}(F_\theta(x_t,t),\epsilon_\theta)$
学生模型本身是单步映射,但实际应用中通过 2-8 步迭代逐步修正噪声,以提升稳定性。
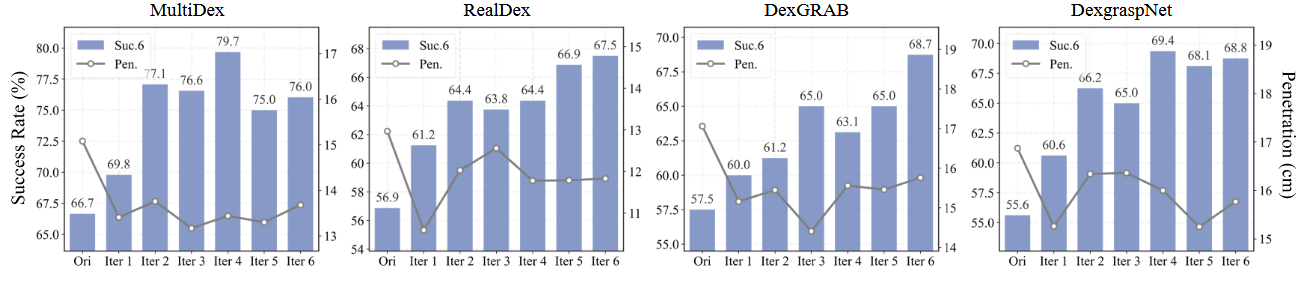
评估指标
Suc.6
Success rate Suc.6 measures the proportion of grasping poses where the object’s displacement does not exceed 2 cm in all six axial directions (±X, ±Y , ±Z), evaluating multi-directional stability.
在仿真器中给物体一个扰动,看物体在六个方向上的移动会不会超过2cm。需要六个方向都小于2cm才算成功。
Suc.1
Suc.1 measures the proportion where displacement does not exceed 2cm in at least one direction, assessing single-direction stability.
在仿真器中给物体一个扰动,看物体在单个方向上的移动会不会超过2cm。
Pen.
Pen. indicates the maximum penetration depth (mm) between the hand and the object, with lower values suggesting more physically plausible grasps.
手与物体之间的最大穿透深度 (mm),值越低表示物理上越合理。
结果如下(论文中的metrics似乎单位错了?):
手部姿态参数表示
抓取姿态 x 由三部分组成: $x=\left\{\theta_h\in\mathbb{R}^{24},T_{\mathrm{global}}\in\mathbb{R}^3,R_{\mathrm{global}}\in SO(3)\right\}$
关节角度
参数: $x= \theta_h\in \mathbb{R}^{24}$
含义:控制手部24个关节的弯曲角度(如手指的屈伸、侧展)。
作用:决定手指的局部形状,例如手指如何包裹物体。
全局平移
参数: $T_{\mathrm{global}}\in\mathbb{R}^3$
含义:手部基坐标系(如掌心)在三维空间中的平移坐标 (x,y,z)。
作用:确定手部相对于目标物体的位置(如手距离物体的远近)。
全局旋转
参数:$ R_{\mathrm{global}}\in SO(3)$
含义:手部基坐标系的三维旋转矩阵(属于特殊正交群 SO(3)),表示手部的朝向(如掌心朝上/朝下)。
作用:决定手部在空间中的摆放方向,影响抓取角度(如正握、侧握)