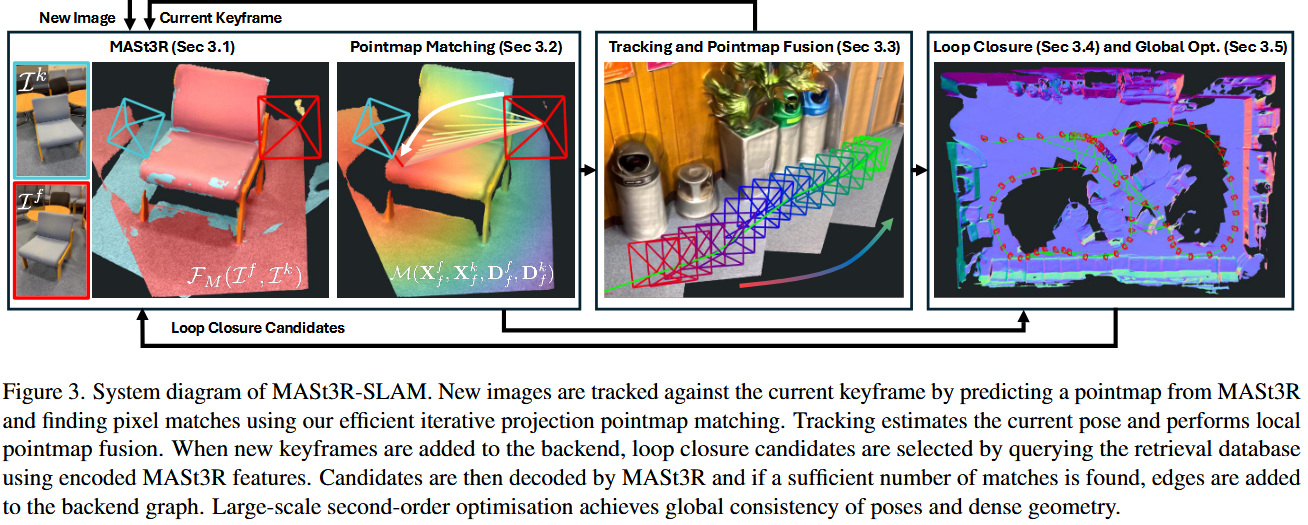
Mast3r - SLAM
定义
dust3r/mast3r 输入$\mathcal{I}^i,\mathcal{I}^j\in\mathbb{R}^{H\times W\times3}$
得到$\mathbf{X}_i^i,\mathbf{X}_i^j\in\mathbb{R}^{H\times W\times3}$及对应的置信度 $\mathrm{C}_i^i,\mathrm{C}_i^j\in\mathbb{R}^{H\times W\times1}$
$\mathbf{X}_j^i$是图片i的点云在相机j下面的坐标
相比于dust3r,mast3r还输出了每个像素的特征向量$\mathrm{D}_i^i,\mathrm{D}_i^j\in\mathbb{R}^{H\times W\times d}$,及$\mathrm{Q}_i^i,\mathrm{Q}_i^j\in\mathbb{R}^{H\times W\times1}$。类似于特征子和描述子。
将mast3r的输出结果合并记为:$\mathcal{F}_M(\mathcal{I}^i,\mathcal{I}^j)$
一对图片的匹配集合表示为:$\mathbf{m}_{i,j}=\mathcal{M}(\mathbf{X}_i^i,\mathbf{X}_i^j,\mathbf{D}_i^i,\mathbf{D}_i^j)$
整体思路
1 前端优化:逐帧优化相机位姿,构建局部地图。
2 后端优化:全局优化所有关键帧和地图点,修正漂移和保证全局一致性。
前端优化
目标有两个:
1 在新帧和最近关键帧之间进行相机位姿的局部优化。
2 在局部范围内融合点地图(点云融合)。
点图匹配

数学推导如下(从几何角度上理解更为直观):

为了进行局部的位姿优化,首先需要找到两张图之间的对应点:
projective data-association:
利用相机投影模型(例如针孔模型或其他中心投影模型,本文用的是射线),将 3D 点投影到图像平面上,并找到对应的像素位置。在投影到的像素周围局部搜索对应的观测点(例如通过颜色、特征等进行匹配)。 通过这种投影与局部搜索,实现高效且准确的点匹配,而不需要全局特征匹配(如耗时的 brute-force 特征匹配)。
但是这个模型需要准确的相机参数->构建相机模型
def : 对于一幅图像中的点云,光线定义为从相机中心指向某个 3D 点的单位向量。 作者采用的方式:基于迭代优化求解,最小化投影光线之间的角度误差优化的参数是: $\mathbf{T}= \begin{bmatrix} s\mathbf{R} & \mathbf{t} \\ 0 & 1 \end{bmatrix}$, 及图片之间的像素的匹配关系
$$\mathbf{p}^*=\arg\min_\mathbf{p}\left\|\psi\left([\mathbf{X}_i^i]_\mathbf{p}\right)-\psi\left(\mathbf{x}\right)\right\|^2.$$$$\left\|\psi_1-\psi_2\right\|^2=2(1-\cos\theta),\quad\cos\theta=\psi_1^T\psi_2.$$
只有外参和尺度,没有估计内参,利用cuda并行加速
过滤点的方式:过滤三维空间中距离相差较大的点(文中没有提到具体的做法)
点图匹配的优化方法
目标: 找到两张图片之间的对应点
初始化:恒等映射,即按像素坐标映射
优化的方程:
$$\mathbf{p}^*=\arg\min_\mathbf{p}\left\|\psi\left([\mathbf{X}_i^i]_\mathbf{p}\right)-\psi\left(\mathbf{x}\right)\right\|^2.$$优化的变量:以第一张图片为参考系,逐像素优化第二张图片的对应点的像素坐标(u,v),这个过程可以在GPU上并行运算(cuda),并且文中提到只要10次迭代就可以收敛(速度比mast3r找对应点的方式更快吗?)
跟踪
估计当前帧(f)和最后一个关键帧(k)的相对位姿变换
什么叫使用网络的单次传递来估计变换?
损失函数: mast3r会估计出图片1的在图片2坐标系下的点云、图片2对应的点云在图片2坐标系下的点云(反过来也是一样的),这两个点云只相差了一个坐标变换矩阵(以及尺度?同一个pair下面也会有尺度不一致吗?)。这个损失函数应该只考虑了置信度较高的特征点对应的像素对应的点云。
$$E_p=\sum_{m,n\in\mathbf{m}_{f,k}}\left\|\frac{\tilde{\mathbf{X}}_{k,n}^k-\mathrm{T}_{kf}\mathrm{X}_{f,m}^f}{w(\mathrm{q}_{m,n},\sigma_p^2)}\right\|_\rho$$$$\mathrm{q}_{m,n}=\sqrt{\mathrm{Q}_{f,m}^f\mathrm{Q}_{f,n}^k}$$q是描述子的内积; (这个$\sigma$没有定义?)
$$w(\mathbf{q},\sigma^2)= \begin{cases} \sigma^2/\mathbf{q} & \mathbf{q}>\mathbf{q}_{min} \\ \infty & \mathrm{otherwise} & & \end{cases}.$$如何解决3D点深度不一致的问题->光线误差(而不是重投影)+点云融合
利用射线的角度误差而非投影误差(这个误差对深度不敏感)
$$E_r=\sum_{m,n\in\mathbf{m}_{f,k}}\left\|\frac{\psi\left(\tilde{\mathbf{X}}_{k,n}^k\right)-\psi\left(\mathbf{T}_{kf}\mathbf{X}_{f,m}^f\right)}{w(\mathbf{q}_{m,n},\sigma_r^2)}\right\|_\rho.$$角度误差是有界的,基于射线的误差对异常值具有鲁棒性。因为:1.相比直接使用 3D 点误差,射线误差(角度误差)更鲁棒,因为它只考虑方向,而不依赖于深度的绝对精度。 避免尺度问题:2.由于单目 SLAM 中的尺度不确定性,使用射线误差能够更好地处理尺度问题。
我们还包括一个关于距离相机中心的距离差的小权重的误差项。这防止了系统在纯旋转情况下退化,但较小的权重避免了像点位误差那样对位姿估计产生偏差。???
点云融合
点云融合的方式,加权平均
$$\tilde{\mathbf{X}}_{k}^{k}\leftarrow\frac{\tilde{\mathbb{C}}_{k}^{k}\tilde{\mathbb{X}}_{k}^{k}+\mathbb{C}_{f}^{k}\left(\mathbb{T}_{kf}\mathbb{X}_{f}^{k}\right)}{\tilde{\mathbb{C}}_{k}^{k}+\mathbb{C}_{f}^{k}},\tilde{\mathbb{C}}_{k}^{k}\leftarrow\tilde{\mathbb{C}}_{k}^{k}+\mathbb{C}_{f}^{k}.$$置信度直接相加吗?->某一个点的置信度会越来越高
后端优化
图的构建以及回环检测
怎么判断一个图片是否是关键帧?
通过mast3r构建一个pair,同时输入最后一个关键帧和当前的图片,计算匹配的像素点的数量,如果这个数量低于某一个值,那就说明这个新加入的图片能够产生足够多的新的点云,因此就把这张图作为关键帧。
graph的顺序是什么?
按照时间顺序串联,同时维护一个边的集合,每次加入两个关键帧之间的边(双向)
局部的回环检测和全局的回环检测
采用MASt3R-SfM使用的聚合选择性匹配内核 (ASMK)框架(?),用于从编码特征进行图像检索。 这样就能找到两张类似的图片来进行回环检测。(但是文章中没有提到增量式建立ASMK框架的过程以及检测到回环之后调整全局位姿的方法?)
后端优化
后端优化的方法,对于边的集合中所有的图片一起进行优化
$$E_g=\sum_{i,j\in\mathcal{E}}\sum_{m,n\in\mathbf{m}_{i,j}}\left\|\frac{\psi\left(\tilde{\mathbf{X}}_{i,m}^i\right)-\psi\left(\mathbf{T}_{ij}\tilde{\mathbf{X}}_{j,n}^j\right)}{w(\mathbf{q}_{m,n},\sigma_r^2)}\right\|_\rho$$假设集合中有N个关键帧,那么形成了2N个边(双向边,形成了回环),每个关键帧有7个自由度(3 个旋转、3 个平移和 1 个尺度)