信息概览
Science Robotics
论文题目: NeuralFeels with neural fields: Visuotactile perception for in-hand manipulation
论文单位: CMU
是否开源: 是
总结: 为了实现类人灵巧操作,机器人必须理解和推理其操作物体的空间关系。特别是在手内操作中,机器人需要估计物体的姿态(位姿)和形状。传统的机器人视觉系统通常面临视觉遮挡的问题,当物体被手或环境遮挡时,视觉数据会变得不完整,从而影响精度。
NeuralFeels方法使用了视觉(RGB-D摄像头)、**触觉(基于视觉的触觉传感器)和本体感知(机器人关节角度)**数据。这些数据通过在线神经场(Neural Field)模型进行处理,结合了多种感知输入,以获得更精确的物体位姿和形状估计
作者使用了Signed Distance Field (SDF),这是一种基于距离的表示方法,可以高效地表示物体的表面。
NeuralFeels方法的一个关键特性是在线学习。在物体与机器人手进行交互时,系统会实时更新物体的3D表示(SDF)和位姿
工作流
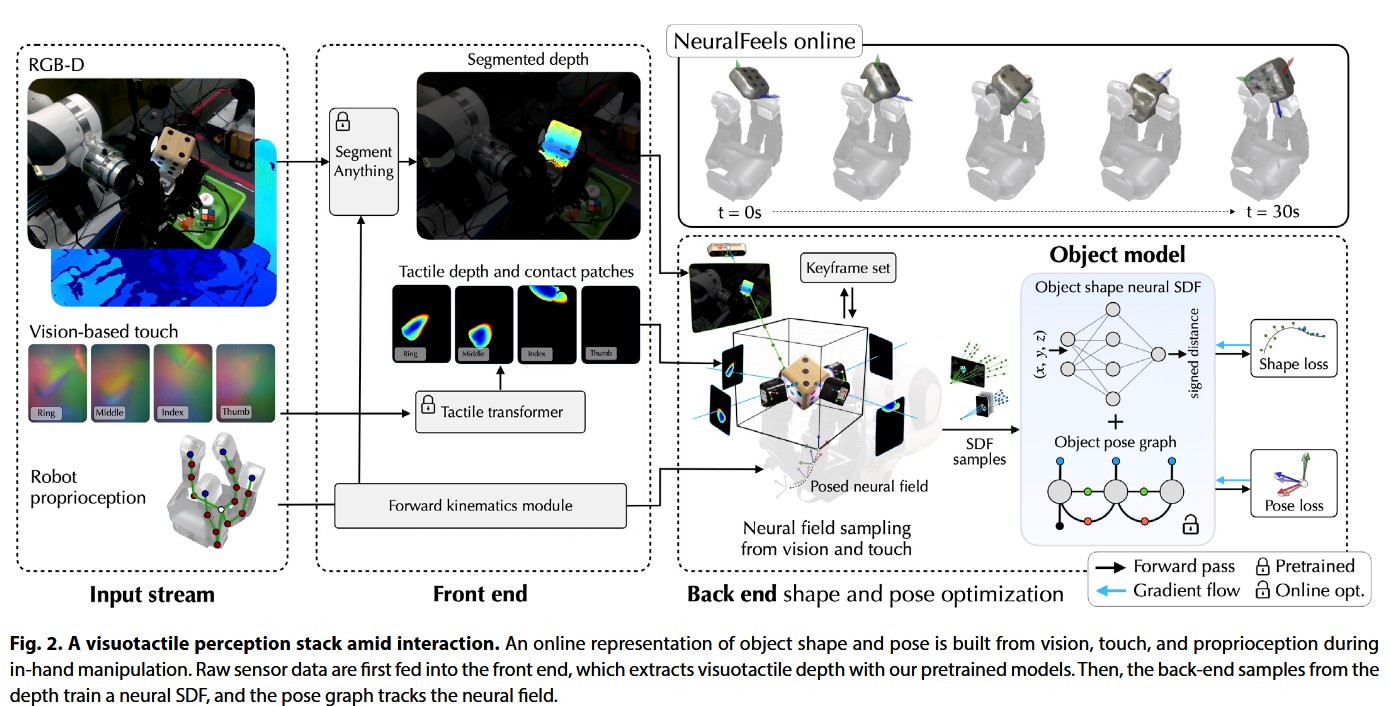 系统首先通过视觉(RGB-D相机)和触觉(指尖DIGIT传感器)获取数据,利用Segment Anything Model(SAM)分割物体区域并排除手部遮挡,同时通过预训练的触觉变压器从触觉图像中提取接触深度;随后,前端处理生成的点云与深度信息输入后端,通过神经符号距离场(SDF)建模物体几何形状,并构建位姿图(包含SDF约束、帧间ICP配准和位姿平滑因子),采用交替优化策略——即固定位姿时通过梯度下降更新神经场参数,固定神经场时通过非线性优化(Levenberg-Marquardt算法)求解物体位姿,同时动态管理关键帧以平衡计算效率与全局一致性,最终在在线交互中实现物体形状的渐进式重建与姿态的稳定跟踪,触觉数据在视觉遮挡或噪声场景下显著补全局部几何信息,提升系统鲁棒性。
系统首先通过视觉(RGB-D相机)和触觉(指尖DIGIT传感器)获取数据,利用Segment Anything Model(SAM)分割物体区域并排除手部遮挡,同时通过预训练的触觉变压器从触觉图像中提取接触深度;随后,前端处理生成的点云与深度信息输入后端,通过神经符号距离场(SDF)建模物体几何形状,并构建位姿图(包含SDF约束、帧间ICP配准和位姿平滑因子),采用交替优化策略——即固定位姿时通过梯度下降更新神经场参数,固定神经场时通过非线性优化(Levenberg-Marquardt算法)求解物体位姿,同时动态管理关键帧以平衡计算效率与全局一致性,最终在在线交互中实现物体形状的渐进式重建与姿态的稳定跟踪,触觉数据在视觉遮挡或噪声场景下显著补全局部几何信息,提升系统鲁棒性。
度量指标
Pose Metric(位姿度量)
首先是位姿,从估计的网格中下采样一些点,并与离其最近的真实点作差
传统的成对距离方法需要在估计点和真实点之间建立逐对对应关系,对于每个估计点,都需要找到多个真实点并计算距离,这样会导致计算量迅速增加,尤其是当物体复杂或者有大量点时,计算量会非常庞大。
ADD-S通过只计算每个估计点和最近点的距离,避免了这种逐对匹配,大大减少了计算的复杂度。每个点只需要找到对应的最近点,而不需要考虑所有可能的点对,这样可以大幅加速计算过程。
??不过这样难道不会陷入局部最优吗?得去代码里仔细看看
Shape Metric(形状度量)
形状度量用来衡量物体形状的重建精度。为了评估物体的形状重建,作者使用了 F-score,这是一个结合了精度(Precision)和召回率(Recall)的指标,通常用于多视角重建任务。
精度(Precision) 精度衡量的是重建的表面点与真实表面点之间的匹配质量。具体来说,它计算的是:
重建的点集中有多少百分比的点,在距离真实表面点 $\tau$(例如5毫米)以内。
召回率(Recall) 召回率衡量的是真实物体表面点被重建点覆盖的程度。具体来说,它计算的是:
真实的物体表面点中有多少百分比的点,可以在重建的点集里找到,并且其距离小于 $\tau$。
F-score 是精度和召回率的调和平均值(harmonic mean),这可以综合考量重建的准确度和完整度,得出一个[0,1]的评分。 F-score 的值越接近 1,表示重建的物体表面越精确,重建的点与真实点之间的距离越小,且重建点尽可能多地覆盖了真实表面。
细节
物体的对齐:为了避免初始化阶段的误差,作者在实验中假设物体的初始位姿是已知的,并且它与真实位姿是对齐的。这意味着,尽管物体的初始位姿是在实验开始时设定的,物体的质心和主轴已经在某种程度上与地面真值对齐.初始化时,物体的坐标系是通过CAD模型的几何质心和主轴方向来设置的,确保物体坐标系与实际操作中的初始姿势匹配。为了保证后续重建的物体位姿不会从中受益,作者在手内物体旋转的5s后才开始做物体位姿和形状的测量,专注与后续的重建和跟踪。
由于细小误差的积累,且没有回环检测,那么随着时间的累积,物体的pose误差会不断累计,不过作者并没有这方面的改进,只是说明他们大部分的实验的形状估计并没有随着时间的延长而恶化。
目标
增量式地重建物体,在线地同时优化网络权重->更新SDF,物体位姿
有一个灵巧手在拿着物体旋转,这个旋转的策略应该是给定的
输入RGBD图像,四个手指的触觉传感器,以及机器人自身关节角旋转的参数
key insights
神经场(Neural Fields)是一种利用神经网络表示和建模3D空间中物体形状的方式。最常见的形式是有符号距离场(Signed Distance Fields,SDF),它通过神经网络来近似描述物体表面的位置。在这种表示中,每一个空间点都有一个标量值,表示到最近表面的距离。
神经场的优势在于,它提供了一种连续的、差分可计算的方式来描述复杂的三维几何形状,相比于离散的表示(例如点云或网格),神经场在内存占用和计算效率上更具优势,且可以进行精确的表面重建。
“姿态化”意味着神经场不仅表示物体的几何形状,还考虑了物体的位置和姿态(即其在三维空间中的方向和位置)。具体来说,NeuralFeels 中的神经场是通过优化物体的姿态(即物体在空间中的位置和朝向)和形状(即物体的几何特征)来动态更新和估计物体的模型。
在NeuralFeels中,物体模型(即神经场)是通过交替优化的方式来估计的:
形状优化:通过优化神经网络来更好地匹配物体的表面。
姿态优化:通过优化姿态图(Pose Graph)来调整物体的相对位置和朝向,确保物体的表面与其姿态保持一致
触觉相关
DIGIT视觉触觉传感器

输入为触觉图像,输出为像素级深度图。
前端
后端
需要讨论的问题
1 这个论文的代码里给的是原始的触觉输入图像,然后他们自己训了一个transformer来输出深度,如果用我们自己的传感器需要作哪些更改?
2 SDF没有颜色信息,用GSDF转高斯?或者还有没有别的方法?从本质上来说,我只是需要物体的形状作监督,只是physgaussian和GIC等代码用的是颜色来作为损失,既然已经有SDF场,有没有什么办法能把sdf离散为粒子?比如sdf->voxel->particle
补充材料
随便记录下
物体的mesh和pose真值的获取
获取真实物体的mesh
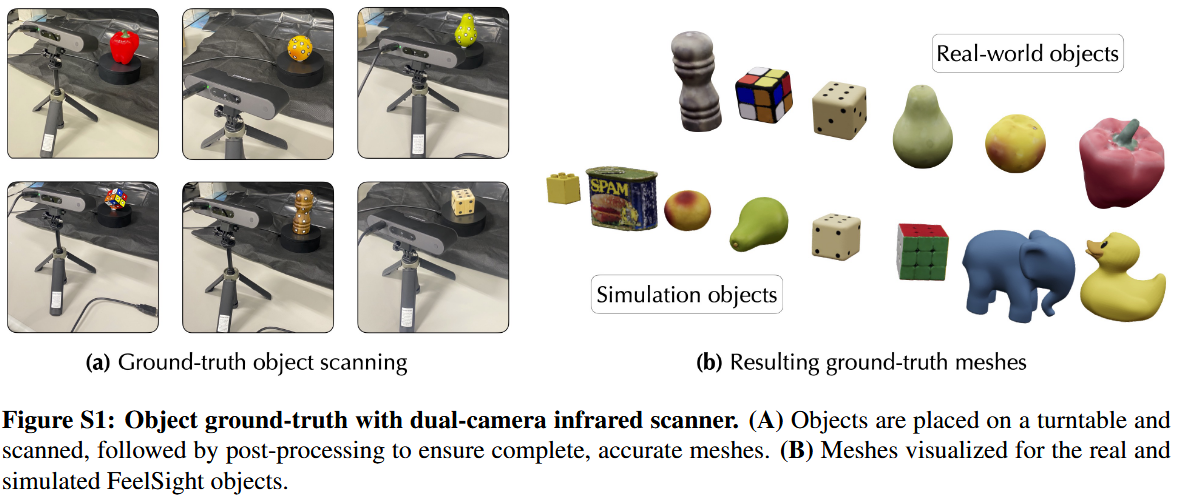
获取真实物体的pose

keyframe选取
两个指标,一个是时间间隔,另一个是将SDF渲染为深度图,与传感器深度图对比计算差异。若平均损失超过阈值 d_thresh?,说明当前SDF模型与观测数据差异较大(例如探测到物体新表面),从信息增益的角度出发?