
尽管当前的视频生成模型已能产生令人满意的效果,但生成的结果中仍常出现不自然的现象(Sora),这些现象往往违背了我们对几何和物理常识的理解,因此近年来,许多研究尝试将物理规律融入视频生成模型来得到更好的结果。与此同时,在机器人领域,大多数研究仍主要聚焦于机器人自身的运动轨迹生成,而对环境及交互物体的感知仍停留在视觉信息的层面,未能充分利用物理规律。因此,这篇文章总结了我对近期工作的一些总结,以及一点点对于这些工作在灵巧手操作上可能应用的思考。
我的想法大致如下:
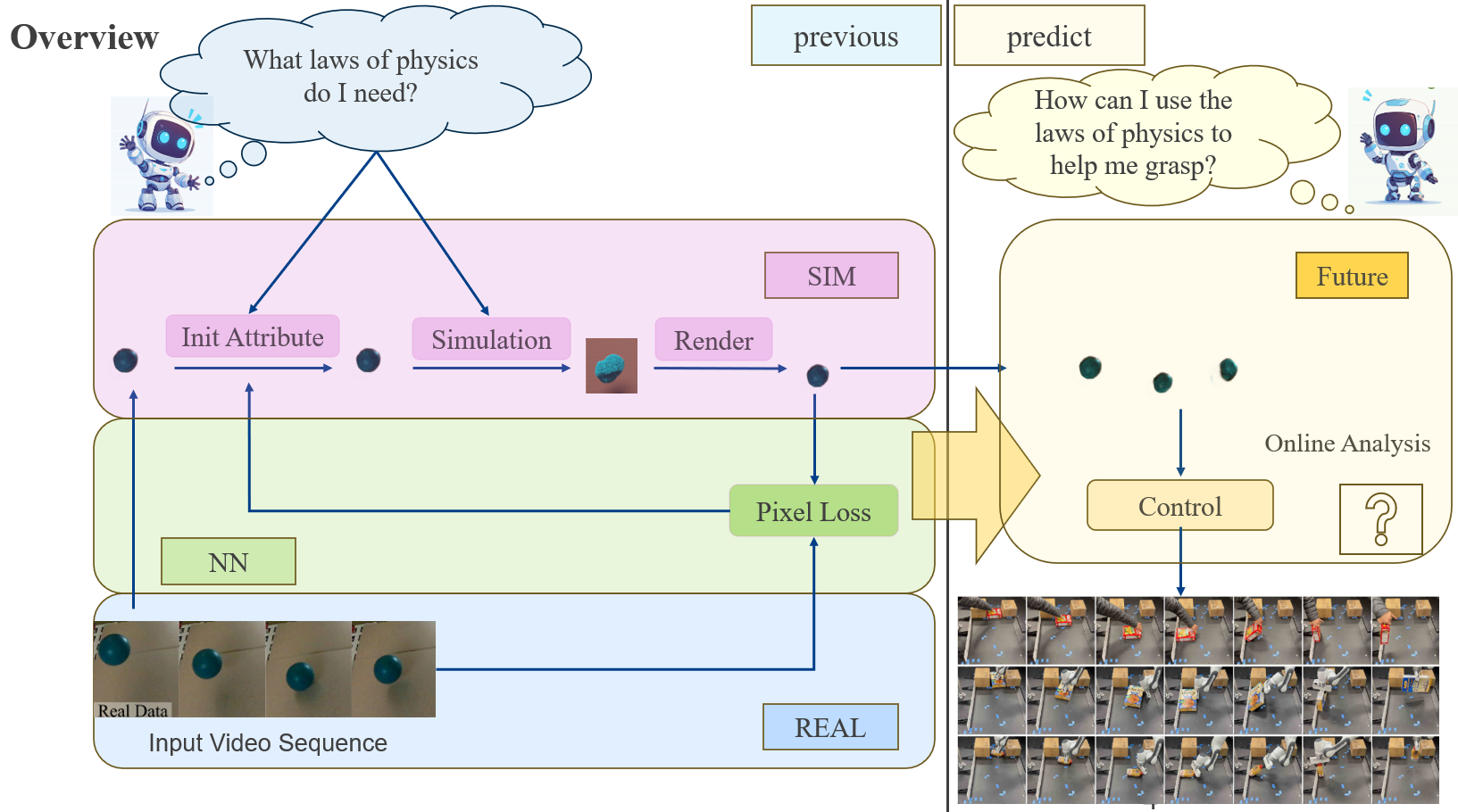
整个工作的pipeline如下:
- 给定一个任务,利用LLM预测我们需要知道哪些物理属性(比如物体的摩擦系数);
- 输入一段视频作为监督信号,从该视频的初始帧开始进行物理仿真,优化物理参数场;
- 得到较为精确的物理参数后,生成/仿真得到该物体在被施加一个力后的响应;
- 在已有的手物交互轨迹基础上,如果能准确预测物体对外力的响应,就能进一步微调手的施力方向和大小,或者将这些信息直接融入轨迹生成过程中,以提升交互精度。
一句话概括就是让机器人理解真实环境中的物理属性,从而更好地辅助操作实现。那么自然而然地会引出两个问题,
首先,如何从环境中恢复物体的物理属性并进行物理仿真?
其次,在机器人已知物体的物理属性后,如何利用这些信息优化灵巧手的操作?
Physics Simulation & Video Generation
事实上,给定视频恢复物理属性(pipeline2)与给定物理属性生成视频(pipeline3)互为反问题(不过我更关注的是生成物体对于外力的响应,并不需要那种精细的视频)。然而,近年来学界的研究更倾向于后者,这一领域的研究主要分为以下三个方向:
物理对齐 Physics Alignment
在语言模型中,对齐(Alignment)指的是通过一系列算法和工程手段,修正模型的行为,使其输出符合预设的安全边界和人类意图。与之对应的,修正视频模型的输出使其满足物理规则的过程就是物理对齐。作为对齐领域的代表性工作,InstructGPT 提出了两种对齐方法:
监督微调(Supervised Fine Tuning,SFT)人工标注高质量的提示(prompt)和回答(output)数据集,通过监督学习的方式微调模型。
基于人类反馈的强化学习(Reinforcement Learning from Human Feedback,RLHF)对同一个提示,模型输出多个回答,人工对这些回答进行比较打分;使用打分的结果训练一个反馈模型(Reward Model),用于评价模型输出的好坏;使用反馈模型对模型进行强化学习,比如近端策略优化(Proximal Policy Gradient,PPO)。
将这两种想法用于视频模型中是比较直观的。对于 SFT,我们就需要使用物理真实的视频作为输入。但是真实世界中的视频当然都是物理真实的,可能的问题是视频动态不够,导致模型没有接受到足够的动态信息。因此像 Cosmos 在预训练阶段就会保证数据能够反映真实物理规则。这主要是通过两点做到的:
- 收集包含大量动态的视频:包括驾驶视频、手部动作、第一人称视角、模拟结果等等。
- 对数据进行过滤:剔除质量低的、缺乏动态的、非物理等的视频,并提取一部分高质量视频作为后训练数据集。
尽管 Cosmos 的论文在 5.3.2 节专门讨论了物理对齐的问题,但是实际上并没有做更多的尝试,只是在几个场景中测试了 Cosmos 生成的结果是否吻合模拟/真实的物理。
对于 RLHF 而言,首要问题是需要一个反馈模型来判别模型输出的结果是否满足物理规律。这方向一个代表工作是 VideoPhy。这篇工作的核心是对市面上十二个视频模型的生成结果进行人工打分,然后训练一个打分网络 VideoCon-Physics。打分分为两个维度,每个维度得分只有 0 或 1:一个是语义的符合程度(Semantic Adherence,SA),一个是是否符合物理常识(Physical Commonsense,PC),结果如下:
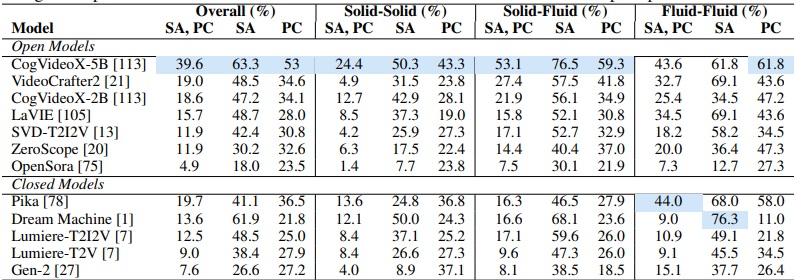
可以发现成绩最好的是开源模型 CogVideoX-5B,但是也只是勉强及格的水平。这方向类似的工作还有 VideoScore,PhyGenBench。理论上有了打分模型之后我们就可以对视频模型进行强化学习对齐了,OnlineVPO 就使用了 VideoScore 作为反馈模型微调了 OpenSora 模型,使其在 VideoScore 得分上超越了其他模型。
整体上来说,物理对齐比较依赖预训练大模型的能力。对于语言模型来说,对齐往往会降低模型在基准测试上的分数,称为支付对齐税(Alignment Tax)。对于视频模型情况应该是类似的,增强其在物理动态方面的能力可能导致其他能力的削弱。因此,一个更本质的问题是,通过预训练的方式大模型是否能够足够泛化地学到物理规律?字节的工作 How Far is Video Generation from World Model? A Physical Law Perspective 是这个方向的一个初步探索。
二维平面模拟 2D Physics
Ok,如果视频模型短期内无法达到我们对于物理规律的需求,那我们是否可以通过加入物理模拟的方式增强这方面的能力呢?由于视频模型都是 2D 的,我们可以先从二维平面上的模拟开始,这一领域分为两个方向,一个是显式地加入物理规律并在屏幕空间上进行模拟,另一个则是隐式地推断物体的动力学信息。
屏幕空间模拟(Screen-space Simulation)指的是绕过 3D 模型,直接在屏幕空间中模拟物体的动态。这方面的一个代表性工作是 PhysGen。
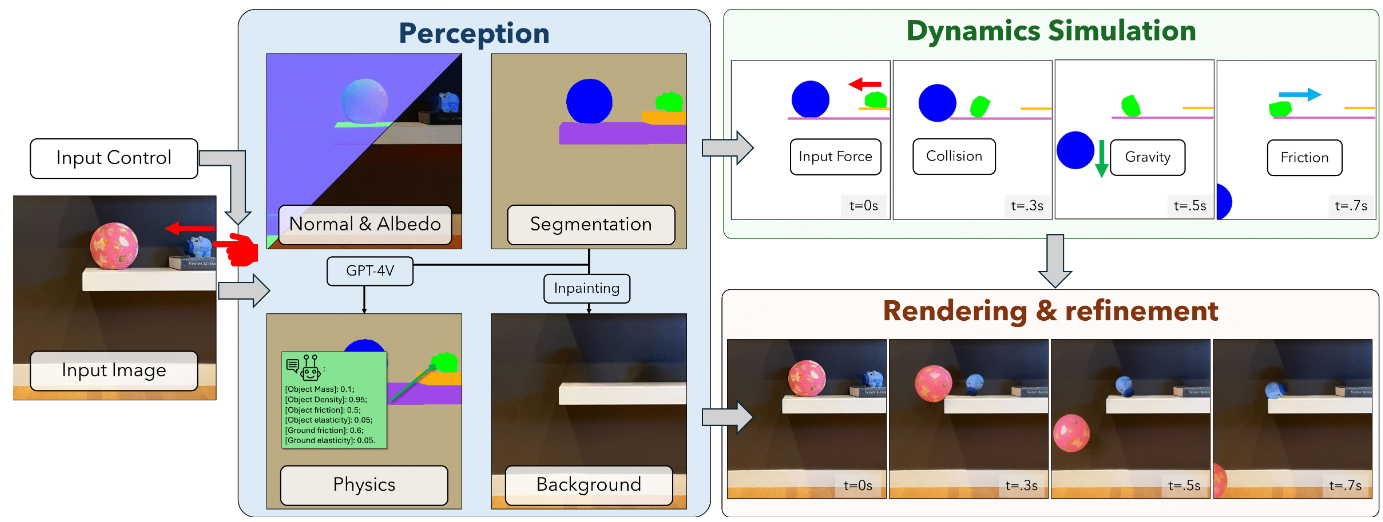
大致的流程分为三步:1. 给定一张初始图片,我们先做分割,并使用图像理解模型获取法向贴图、语义等信息,然后使用大语言模型推测对应的材质;2. 使用屏幕空间的 2D 模拟器进行模拟(刚体模拟);3. 使用视频模型将模拟结果与法向贴图等整合起来,得到最终视频。可以发现,这个流程中其实并不需要大模型生成动态,大模型提供的是一个满足时间连续性的"渲染器",将模拟结果渲染成视频。最近的 PhysAnimator 也是这个思路,不过将模拟的对象进一步扩展到了布料这样的软性材料。
当然,也有不显式加入物理模拟的方式来实现图片上的动力学的工作,而是通过分析图片中物体的振动规律得到信息,并利用这些信息来推断物体的物理特性和驱动它们运动的力,这一工作最早可以追溯到Davis的博士论文Visual vibration analysis。如果有了物体对于一个已知力的响应,那么我们是不是就可以在不知道物理规律的前提下分析一个物体对于未知的力的响应了呢(类似于反馈-控制,黑盒模型)?2024年的CVPR Best Paper Generative Image Dynamics 就做了这样的一件事。与PhysGen不同,这篇论文并没有显式地建模出物体的运动规律,而是只学习到了振动频率(事实上,物体振动频率满足该规律:$\omega = \sqrt{\frac{k}{m}}$),即学习每个像素点的振动规律(利用傅里叶变换分解,学习的参数是傅里叶的系数)。在不考虑训练成本的情况下,相比于显式地模拟,这种方式的推理速度肯定更快,但是显然只能局限于振动这种简单的物理规律,当然,通过改变基函数的方式(比如把傅里叶级数换成勒让德级数)也许可以将该方法推广到更多真实情景,这也是一个值得探索的方向。
总的来说,在二维平面上的模拟的优点很明显,我们能够对生成的结果进行非常精确的控制,并且在小幅度内基本满足我们对物理规则的认知。但是缺点同样很明显,由于我们是在屏幕空间做分割和模拟,我们永远只能生成物体一面的结果,像布料的遮挡褶皱也无法处理。并且,生成结果的视角只能是固定的。这使得这类方法只适用于生成动态壁纸这样比较受限的应用,不能作为通用的视频生成方法。
不过我觉得PhysGen的思维范式很好,如果要继续往下做的话我更倾向于在该工作上的框架上去做。
三维空间模拟 3D Physics
既然 2D 的模拟终究是妥协,那不如我们直接回到三维模拟。回顾传统的图形管线,生成视频的过程大致可以分为准备3D 资产、进行模拟、渲染结果这三步。这三步中预训练的视频模型可以充当一个非常好的渲染器,比如下图展示的,Cosmos 可以将三维模拟的结果风格迁移到真实场景的视频。


在有 3D 资产和物理参数的基础上,模拟也不是一个困难的问题。传统模拟算法在平衡模拟效果和速度上已经提供了非常多的选择。因此最大的问题在于第一步:对于用户给定的一个语言提示,或者是初始帧,如何获取对应的 3D 资产。对应这两种情况我们可以看到两种解决方法,一是训练文本生成 3D 资产的模型,二是从真实图片中重建。
首先,世面上已经有很多专注做文本生成 3D 资产的 AI,比如 Rodin,Meshy 等,可以直接将这些模型导入到像 Houdini、Blender 这样的图形软件中进行模拟。之前受到很多关注的 Genesis 想做的就是这个思路。另一方面,过程建模(Procedural Modeling)使用形式语言或者节点化的方式描述模型的生成过程,可以将 3D 模型与文本直接联系起来。比如 SVG 图片使用 html 标记语言,CAD 模型可以完全用代码表示,Houdini 用节点系统描述模型等等。在有了代码化的描述之后,我们就可以通过语言模型去生成这些代码,也就生成了 3D 模型。Infinigen 通过 Blender 构建了描述自然和室内场景的过程建模语言,因此可以实现文本生成三维场景。GPT4Motion 通过 Blender 实现了无训练,直接从文本生成视频的整个流水线。
如果我们的任务是从初始帧生成视频,就可以考虑从图片重建出 3D 模型。PhysMotion 使用的方法就是从单张图片进行 Gaussian Splatting 的重建,然后接入物质点法进行模拟,最后经过视频模型进行渲染。如果我们的单视角重建(本质上是对其他视角的生成任务)足够好,那么生成视频的质量就有保证。但是话又说回来,我们不正是应该利用预训练视频模型的能力来帮助单视角生成的任务吗?为什么反而抛弃了大模型在这方面的能力而只把大模型作为一个渲染器呢?
我们可以发现,如果只是用大模型去增强现有的图形管线,那么不可避免的需要很长的管线,并且没有充分利用大模型的能力。最理想的情况是,我们用最少的规则限制和控制信号,提供最基础的三维物理和几何的保证,其他的交给预训练模型补充细节。在这个方向上,CineMaster 是一个很有意思的尝试,只通过最简单的包围盒作为条件,就能实现很好的视频控制生成效果。
推断物理信息
前文提到的都是在有物理信息的情况下进行仿真/生成的工作(也就是pipeline3),如果我们希望将这一概念应用于机器人操作,那么关键问题就在于:如何估计现实世界中物体的物理参数?这是一个极具挑战性的问题,因为目前市面上很少有数据集能够提供包括物体质量、弹性系数等在内的各种物理信息。因此,依赖于大规模数据集进行学习来解决这一问题变得非常困难,特别是当数据集质量较低且规模较小时,模型的泛化能力也会受到限制。那么,如何应对这一挑战呢?如果我们选择依赖物理仿真,是否能够提升模型的泛化能力呢?毕竟,像牛顿定律等自然科学规律是普适的。然而,物理仿真对算法的精度要求非常高。基于此,一个较为可行的初步思路是将模型学习与物理仿真结合:首先通过模型学习来获取物体的初始物理属性,如质量、速度等;然后借助传统物理模拟来预测物体未来的运动规律,最后再用神经网络做微调。
在这个方向,蒋陈凡夫他们组在此基础上做了很多相似的工作,最为出名的是PAC-Nerf
与PhysGaussian。他们的思想非常朴素,但是却很有用。其整体框架如下:
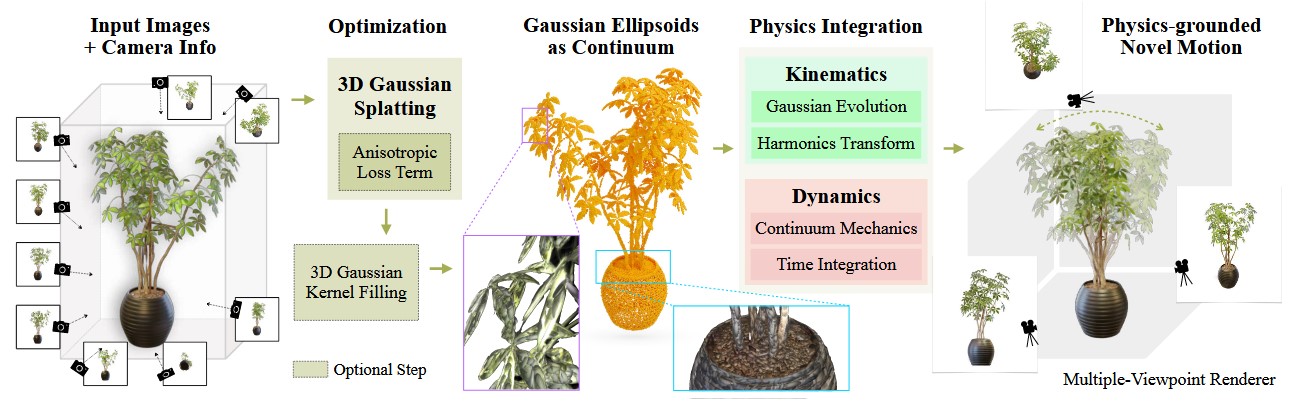
在此基础上,还有两个工作,分别是Physdreamer和DreamGaussian,但是都是一些incremental的工作而且做的都是偏生成方向。Physdreamer应该是这个领域较新的成果了,他们结合了PhysGaussian和DreamGaussian两篇工作,简单点说就是PhysGaussian用了多帧的真实视频作为输入(监督信号),恢复物理属性后,再去预测渲染未来的视频帧,而Physdreamer则只输入视频的第一帧,由第一帧图片生成后续的帧,并将其作为监督信号,再接入PhysGaussian的框架。缺点是显而易见的,生成的视频质量肯定没办法和真实的视频相比的,而且二者之间的误差肯定会随着时间的推移增加,所以他们只选择了前面生成的10帧左右作为监督,那么也就无法生成长视频序列了。而且他们的结果如下:
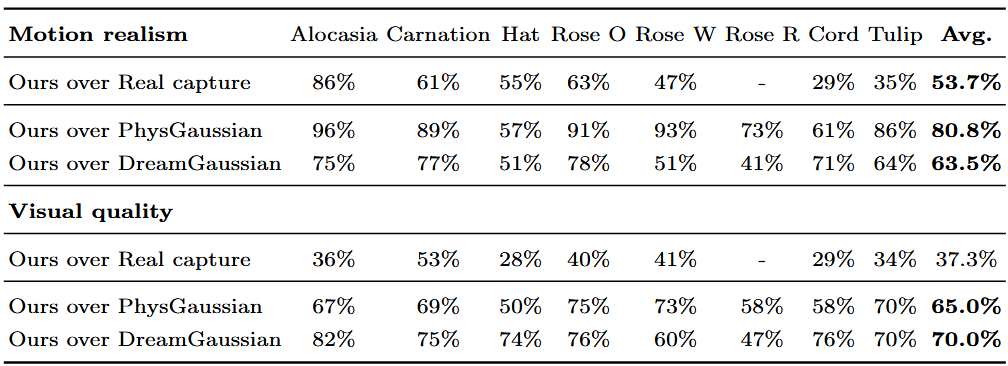
这些评分的意思,比如上面表格的第一个内容表示,对于alocosia(这是一种植物)的视频生成,有86%的人认为他们生成的视频在motion realism的指标下比真实的视频还要好,不过都是人工打分的指标,感觉没啥参考性。而且如果想用到操作的领域,用生成去做肯定是不合适的。不过他们的工作中有一个我觉得还不错的点,他们对于所有的Gaussian点做了knn下采样,也就是只对所谓的driven-particle作仿真,这一点大大加快了仿真的速度。又联想到最近的一篇文章A Grid-Free Fluid Solver based on Gaussian Spatial Representation,这篇工作看格式应该是要投SIGGRAPH的,他们是在PhysGaussian的基础上加速了流体的仿真,简单点说就是原本3DGS核携带的信息是球谐函数,他们把这个信息改成了物理属性,或者可以这么理解,本来3DGS渲染的是RGB,他们改成了渲染速度矢量($V_x, V_y, V_z$)。这个思路我感觉挺好的,而且可以和之前knn下采样的思路结合,我们可以在这个基础上继续加新的东西,而且他们的代码还没有开源,所以我最近有时间的话想从头复现下这篇论文,顺便学习下cuda的代码。
总的来说,我个人感觉这个领域做的人比较少,而且这些工作的不足之处也非常明显,比如首先他们不能将物体的前景与背景分离开来(比如可以参考PhysGen的pipeline,并用LOTUS做分割?),其次他们还是只能模拟简单的物理规律,比如他们都把花朵建模为了纯粹的弹性-质点模型,而且在物理规律模拟的过程中都是比较传统的算法,这对于机器人的操作来说都是必须要解决的问题,我感觉这个领域还是值得研究的。
机器人中的应用 Application in Robot
在机器人领域的调研中,最符合我idea的工作是这篇23年的RAL DANOs。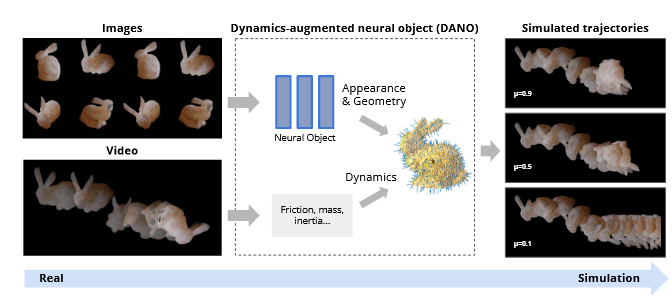
可以参考他们的视频作进一步的了解。
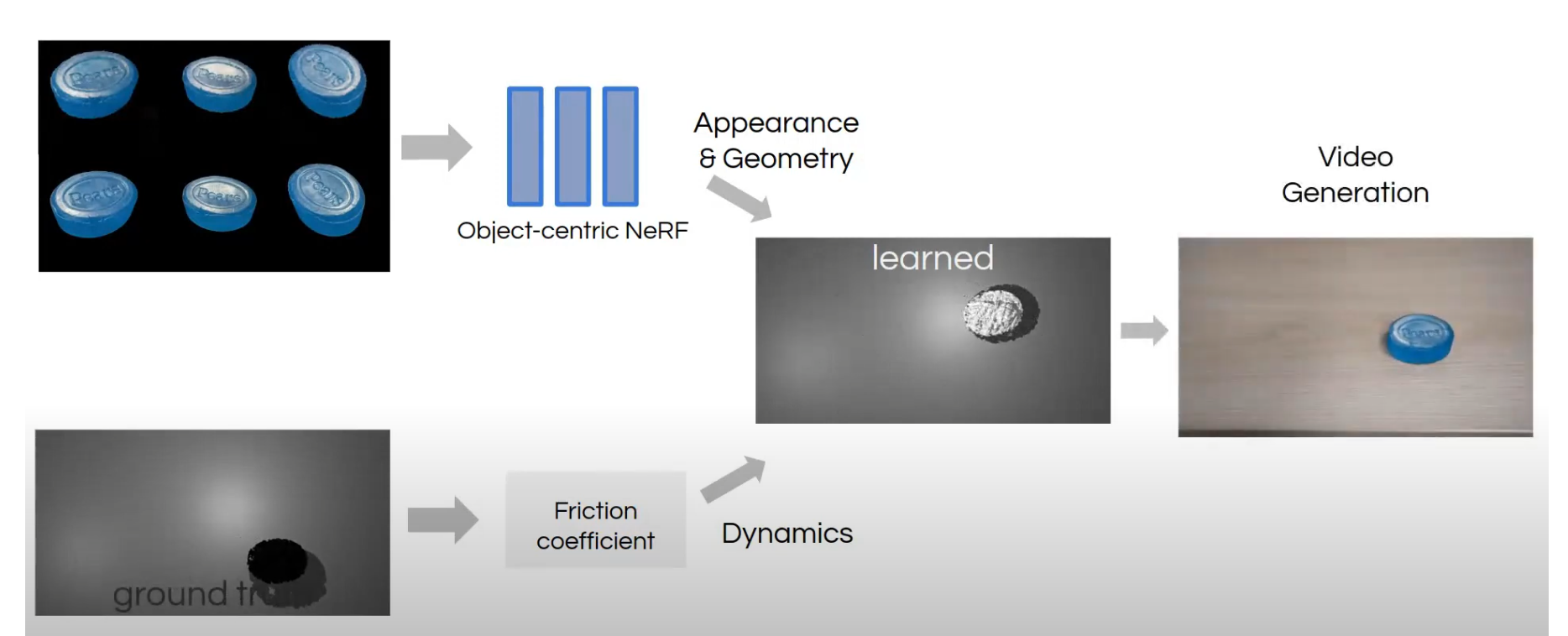
他们的工作是通过纯粹的视觉信息来估计物体的质量,重心,摩擦系数这些属性并辅助机械爪工作,由于是23年的工作,所以他们的框架还是建立在Nerf的基础上的,也就是先建立一个体素场,然后在体素的密度和质量之间,通过神经网络的方式建立一个映射,从而恢复出物体的属性。而且他们还在实物实验上验证了他们的结果,不过这个实物实验比较简单,就是一个肥皂在桌子上滑动,然后预测摩擦力/重力,算出物体的运动规律。
那么由这个工作出发,自然地会想到两条路径。首先,目前,3DGS技术已经被广泛应用,并且相比NeRF,其基于点云的表示方式在物理仿真中更具优势。因此,直接将 NeRF替换为3DGS是一个显而易见的改进方向。这个工作一眼就能看出来能和PhysGaussian结合,虽然我没找到相关工作,但肯定有人会去做,不过别人可能是普通的二爪机械手,我们是灵巧手,而且还能加入触觉信息,这也是我觉得一个可以探索的方向。
其次由这个工作,我还联想到了很多预训练上的工作,例如,在现实任务中,机械手可能难以直接抓取桌面上的一张卡片,而更合理的策略是先将卡片推到桌子的边缘,再进行夹取。本质上,这一推卡片的过程与上述预测摩擦力/重力的方法是相似的,都涉及物理信息的推理与利用。然而,据我观察,大部分机器人领域的研究仍然主要关注于抓取姿态的生成,即如何在几何层面找到最优的抓取方式,而对物体的物理属性(如摩擦、质心、变形)以及环境因素的考量较少。因此,我的研究想法正是希望从物理信息的角度出发,探索更加智能的抓取策略。(如果后续要做这个方向上的工作,我希望能从这个简单的任务(推卡片)开始做)
有人可能会质疑:如果目标是执行某些运动学任务(如推卡片、打乒乓球等),为什么不直接用端到端控制器进行学习?目前已有研究通过强化学习等方法,成功训练出了能够打乒乓球或羽毛球的机器人,是否还有必要引入物理建模?
首先,从直觉上来说,我觉得通过物理规律建模得到的结果可以泛化到很多未知的情境中,端到端的控制方法虽然可以在特定任务上表现出色,但它们通常是基于数据驱动的黑盒模型,容易受到环境因素(如颜色、光照变化等)的干扰。而基于物理规律的建模方法则能够泛化到更多未知场景,不依赖于特定数据分布。
其次,按照我文章一开始提出的overview,哪一个环节出现了问题,对于我来说都是可控的,这种可控性使得物理建模能够更好地与新兴的研究成果结合(比如之前提到的lotus),并进行模块化优化。而端到端学习往往难以解释模型的决策逻辑,并且对于计算资源的消耗量巨大。
第三,打乒乓球这种工作只能局限于运动学模型,而对于更精细的操作(如灵巧手抓取柔性物体、操纵复杂工具、物体局部形变等),物理仿真能够提供更完整的解释。例如,在精细抓取任务中,局部形变、摩擦力、微观接触点的作用不可忽视,而这些信息很难通过端到端的黑盒方法直接学习到。