论文信息
信息概览
ECCV 2024 Oral Presentation
论文题目: PhysDreamer: Physics-Based Interaction with 3D Objects via Video Generation
论文单位: MIT
是否开源: 是
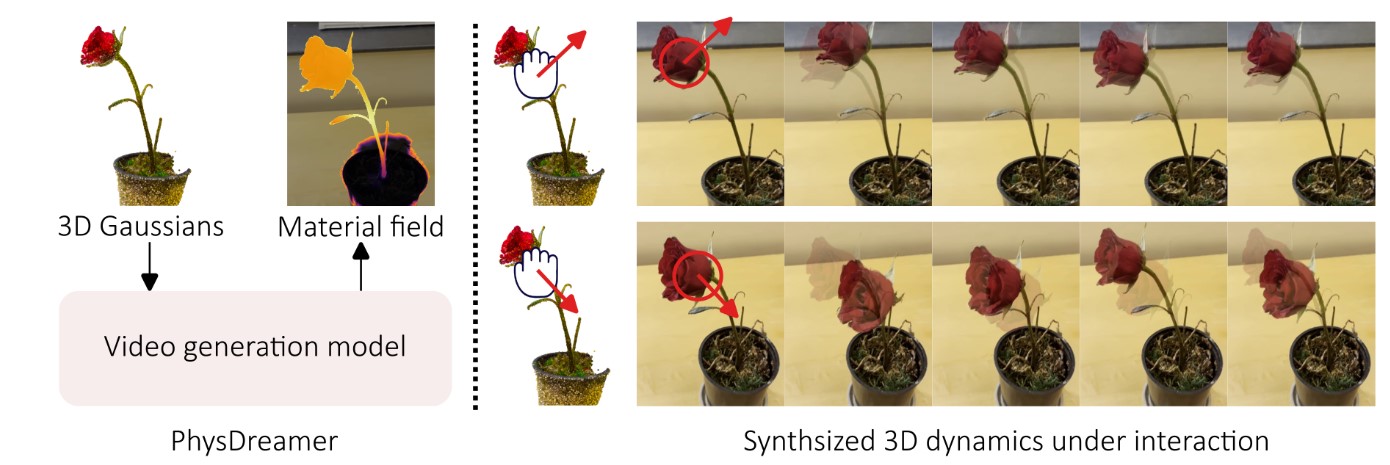
总结: 一种基于物理学的方法,通过利用视频生成模型学习的对象动力学先验,赋予静态3D对象交互式动力学,也就是使静态3D对象能够以物理上似乎合理的方式动态响应交互刺激。
该方法使用3D高斯粒子表示物体,使用神经场建模材料属性,并通过可微分仿真(使用材料点法,MPM)模拟动态。
论文思路
问题:给一张图片,比如一朵花,想知道这朵花在微风吹过后的动态信息,也就是求一个物体对于新物理交互的响应。
但是求解这个响应,需要对物体的性质有较为准确的估计(比如两种弹性系数不同的弹簧,对其施加相同大小和方向的力,其变形显然是不一样的)。
而这个性质是很难测量的,或者说难以形成大规模的数据集以供学习。
但是人类能从观察物理世界和与物理世界互动中获得的物理先验知识,受此启发,作者从大量的视频先验中学习动力学先验,
为了简化,这篇文章只对弹性物体做了仿真,那么估计的物理属性,有质量、杨氏模量和泊松比。质量等于密度乘体积,论文中粒子的体积是体素的体积除以其中包含的粒子数,密度是给定的常数,泊松比也是给定的常数,所以最后优化的只是一个杨氏模量的场。
论文的关键思想是生成运动中物体的合理demo,比如一朵花,他把花离散为很多稠密的点,但这些点不是同构的,因此每个点的杨氏模量都不一样,然后按照物理属性去优化材质场E以匹配这个合成的运动。 我们首先从某个视点为 3D 场景出发渲染静态图像。然后,我们利用图像到视频模型(SVD)生成一个短视频剪辑 {$I_0$, $I_1$, . . . , $I_T$ },描绘对象的真实运动,这个生成的模型是GT来监督模拟得到的图像,然后再通过可微分模拟和可微渲染来优化材料场E(x)和初始速度场$v_0$(x),使得模拟的渲染视频与生成的视频匹配。 但其实我觉得核心的部分还是图中下面的箭头,也就是PhysGaussian的工作比较重要。
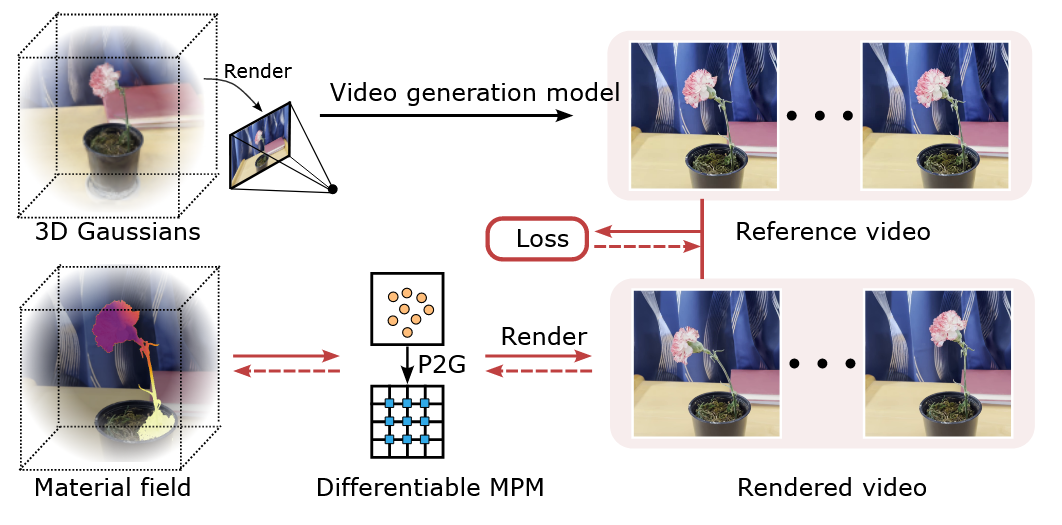
细节部分
仿照PhysGaussian内部填充?
核心的仿真原理:
$$ \rho \frac{D v}{D t} = \nabla \cdot \sigma + f, \frac{D \rho}{D t} + \rho \nabla \cdot v = 0 $$v 是欧拉视角,密度是常量,f是外力。
MPM的实现细节需要单独花时间细看。
总体可以概括如下:
$$ x^{t+1}, v^{t+1}, F^{t+1}, C^{t+1} = S(x^{t}, v^{t}, F^{t}, C^{t}, \theta , \Delta t) $$F和C分别是局部变形场的梯度和应力场的梯度,$\theta$ 代表所有的物理量,在文章里代表E,$\Delta \approx 1 \times 10^{-4}$,仿真了100步。
对于每一步,按如下公式渲染:
$$ \hat{I}^t = F_{render}(x^t, \alpha, R^t, \Sigma, c) $$R代表所有粒子的旋转矩阵,
优化的参数是杨氏模量和初始帧的速度,损失函数定义如下:
$$ L^t = \lambda L_1(\hat{I}^t, I^t) + (1-\lambda)L_{D-SSIM}(\hat{I}^t, I^t) $$创新点(MPM加速)
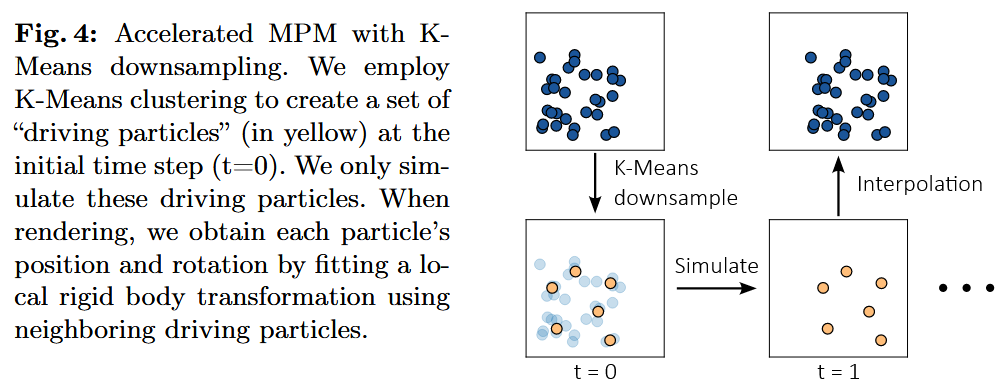
高斯模型包含成千上万个点,这对于模拟来说效率较低。因此,本文采用了下采样方法,每个下采样后的点能够有效描述其对应领域的信息。此外,下采样对3D几何形状(3DGS)的表征同样至关重要。因为3DGS表征存在过于局部化的问题(不同区域之间的表征可能会出现突变或不连贯),这会导致空间表征的不连续性。通过下采样后,每个点包含了其领域的信息,从而有可能推动表征向混合高斯模型(mixture-Gaussian)方向发展,使得空间的整体表示更加连续。这样的方法可能为将三维场景表示为一串序列提供了思路,可以进一步应用于MLLM。例如,可以将该序列视作一个Encoder-Decoder模型,并通过重建信息作为监督信号进行训练。
结果
数据集:八个真实场景,大部分是花,这个作为对照组
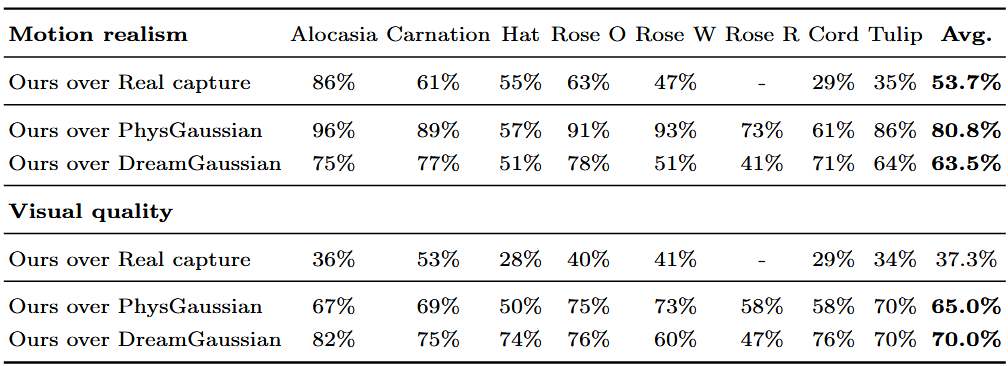
其实没什么意义,因为本身这篇论文是在前两篇的基础上做的,而且PhysGaussian没有优化物理参数,DreamGaussian没有物理假设。。
讨论
视频生成的方式

用SVD采样得到了14帧的信息作为监督。
疑问的点,text-prompt怎么设计,比如花在空中摇摆,或者被人碰了一下,怎么去量化这个幅度?
loss的设计
用生成得到的视频监督是否合理? 因为整个3DGS的参数很多,这篇文章只是监督了E,而其他的位置,速度等信息都是仿真算出来的,所以DoF,或者说优化的参数空间其实比较小。但是如果要学习更多的物理信息,只用SVD去监督肯定不合理。
其次,生成得到的视频离真实场景还是有差别,所以还是要做一个trade-off,一种方法是减少生成视频对模型的影响,例如使用结构损失作为损失函数,或者将生成的视频帧作为guidance来进行distillation,另一种是降低估计的Dof,想这篇文章做的那样,固定泊松比和质量,只估计杨氏模量,第三种方式是提高视频生成的能力,脱离SDS损失函数的监督,转向全监督学习,即让生成的视频与真实场景之间有更多直接的监督。