
之前提到的idea是在Physdreamer的基础上做分割,分割完了之后再在真实的场景上作预测和仿真。 最近突然发现今年的CVPR上有很多文章已经把我想做的事做完了,索性我就把今年CVPR里和我想做的领域相似的论文都看了一遍,并作了简短的总结如下,并在之后提出了一个新的idea。
CVPR 2025
简要回顾
PACNerf (ICLR 2023 Notable) 开创性的工作,没有解决前景背景的分离,在现实世界中的仿真精度很低(体素表示的几何精度很低),需要手动设置材料的类别,然后优化得到材料的参数(简单解释一下,比如一个物体的重量是1kg,重量-类别;1kg-参数),但是可以作弹性仿真、粘性仿真等等;
PieNerf (CVPR 2024) 优化了PACNerf在大扭曲情况下纹理失真的问题,缺点同PACNerf;
PhysGaussian (CVPR 2024 Highlight) 开创性的工作 不能在现实中仿真,没有解决前景背景的分离,需要手动设置材料的类别+参数,只能作简单的弹性仿真;
PhysDreamer (ECCV 2024 Oral) 在PhysGaussian上优化,用生成的视频作监督优化得到材料的参数,但是仍然需要手动设置材料的类别,其余缺点同PhysGaussian;
VRGS (SIGGRAPH 2024) 在PhysGaussian 做了一个用户自定义施加力的功能,有简单的分割,其余缺点同上;
PhysGen (ECCV 2024) 独立于上述工作,是二维平面的物理仿真,基本没有上述工作的缺点,利用大模型作材料预测,且二维的分割比较简单,但是只能做刚体模拟,连弹性仿真都做不了,但是二维平面的仿真上他们还可以设置材料的反光率等等,这点在三维环境中就比较难做了;
Generative Image Dynamics (CVPR 2024 Best Paper) 独立于上述工作,二维平面的可交互弹性仿真,无需显示指定材料,输入力,直接输出响应;
DecoupledGaussian
论文题目:DecoupledGaussian: Object-Scene Decoupling for Physics-Based Interaction
该工作的核心亮点在于分割
此前所有的研究都无法保证前景与背景的完全分离,即使在2D空间上做了好的segmentation,也很难保证3D中点云的分割,而重建出精细的表面对于物理仿真相当重要,这篇工作的贡献点就在于:1 允许对象独立于初始接触表面移动;2 当物体和场景分离后,还能补全物体和场景的结构;
效果如下:

整个框架如下:
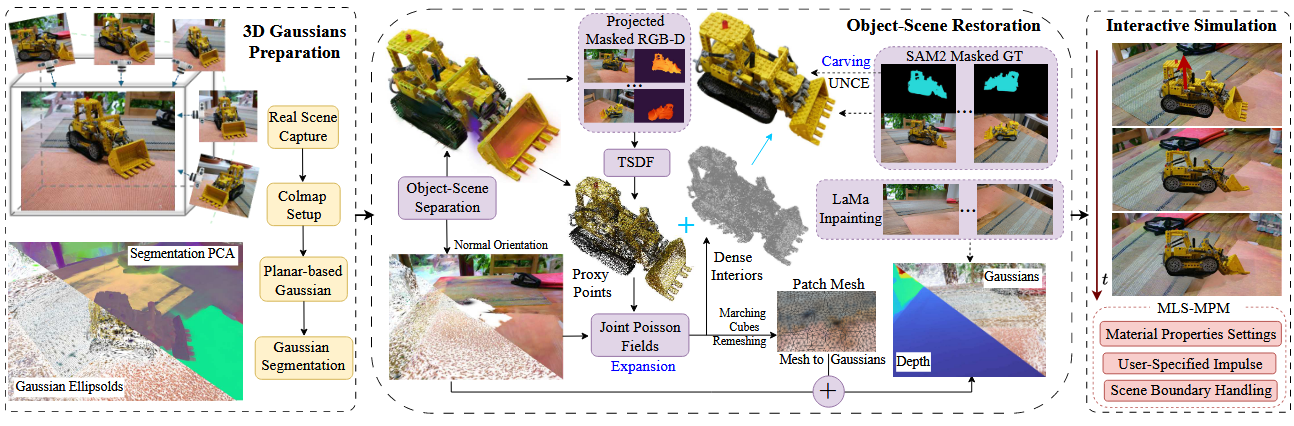
首先还是传统的输入多视图图片+colmap+恢复高斯,然后将高斯分布压缩为与场景表面对齐的近似局部平面(这里具体的理论推导在PGSR中,不过我还没来得及仔细看)。PGSR就是压扁高斯点云(平面高斯),使其能正确对齐实际场景表面(不然可能出现浮动伪影)。而且被压扁的高斯优化更快速、稳定(只需要沿法线优化)。
有了一层层平面的高斯之后,然后要识别哪些高斯点属于物体,哪些属于背景。
具体来说,这篇文章是用语义特征分割的,即每个高斯点都会被赋予一个32维的特征向量,描述其在多视图(用于联合的优化)下的语义信息,然后再通过一个MLP(单层神经网络),将这些特征映射到不同类别(物体或场景)。这个具体实现的细节是一篇2024的ECCV Gaussian grouping 加2024年的SIGGRAPHVR-GS,本质上应该还是SAM,具体细节我也还没看。
然后就是这篇文章最大的创新点,用Joint Poisson Fields同时恢复分离后物体和背景场景几何形态,灵感应该是来源于一篇13年的SIGGRAPH。 由于物体和背景在拍摄时是连接在一起的,因此在分离后,原本被遮挡的部分需要补全和修复。例如,一个花盆在桌子上,如果直接移除,桌面上可能会留下不平滑的痕迹,或者花盆底部会变形。
文中的方法是同时计算计算物体的泊松指示函数$X_O$和背景的泊松指示函数$X_S$。如果 $X_{O(S)}(x)>0.5$,表示该点属于物体(或背景),如果泊松重建认为有的点同时属于物体和背景,那就直接当成背景,因为背景通常更加稳定。而且文章说Joint Poisson Fields自动生成平滑、封闭的3D表面???(例如,如果我们想要分离桌子上的一个花瓶,泊松重建会确保花瓶底部在分离后是封闭的,而不是一个空洞)
其次,高斯点的$\alpha$混合 (alpha blending) 可能导致多个高斯点的融合,真实表面的位置会受到影响,甚至出现几何扩展或重影,所以他们在现有高斯的基础上生成了代理高斯。
具体来说,他们用了TSDF的方法,通过设置高斯点的$\alpha$值,使得除了目标物体之外的所有高斯点透明,从而获得物体的二值掩码。设定一个 3D 体素网格。对于每个深度图 D(p),计算 TSDF 值,并与已有的 TSDF 体素进行加权平均。V(x),每个体素存储一个TSDF值。从TSDF体素网格中提取代理点(TSDF值从正变负的位置,代表物体的真实表面),有了表面之后,再用一个他们自己的算法把之前的高斯插值到表面上的高斯,这个新的高斯就是代理高斯(proxy)。
有了表面之后,还要做内部填充,不然做不了仿真(例如对于一个分离出的雕塑,我们需要在雕塑的内部填充粒子,使其不会在掉落时崩塌),文中的处理方法是在$X_{O}>0.5$的泊松场区域内部提取密集粒子,当然这是因为Joint Poisson Fields能自动生成封闭的3D表面(虽然我不太理解为啥封闭,但是对于封闭的表面这样处理是合理的)。
存在的问题
论文有三个重要的算法,分别是PGSR,Joint Poisson Fields(泊松指示函数)和从TSDF表面得到代理高斯的算法,但是都没仔细介绍,所以我还需要仔细看看详细的理论推导过程。
然后这篇文章本身存在的问题,首先这篇文章还没开源,没有代码,其次,那个多视图TSDF/物体掩码混合的过程需要将近100s,这个肯定可以优化,当然这篇工作还是为了重建精细的表面,才需要这个算法,而且对于时间其实没有太多的要求,然后这里的材料属性仍然需要手动设定。
PhysFlow
该工作的核心亮点在于真实世界仿真+不需要手动设置材料参数
整体框架如下:
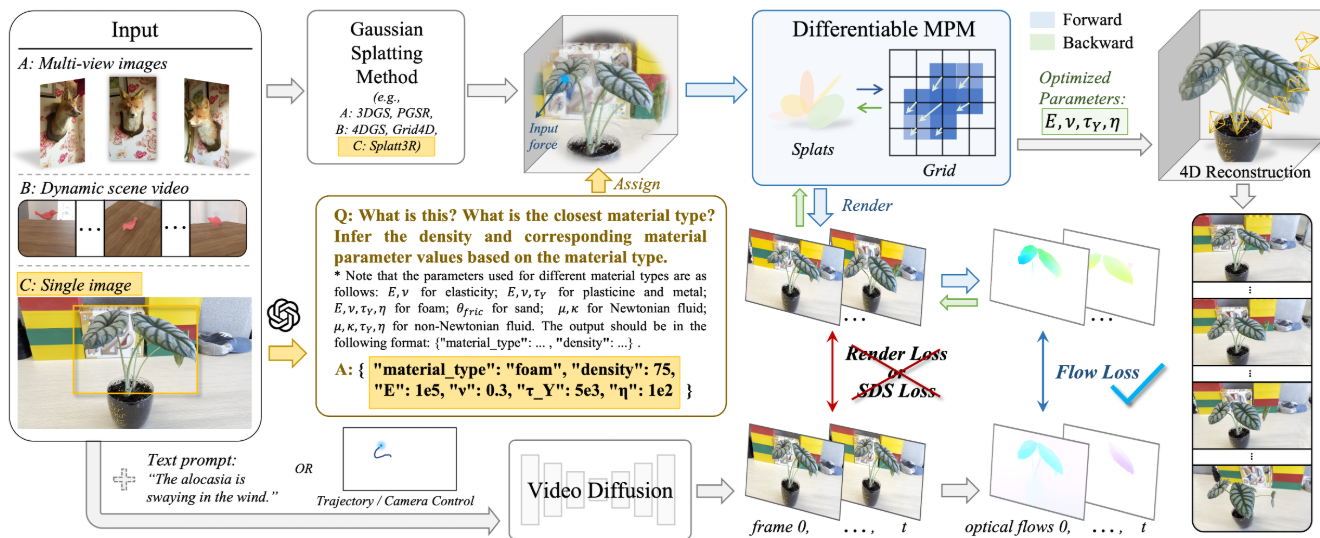
思路简单地说就是在Physdreamer的基础上,把他们那个SDS loss改成了光流的loss,然后再仿照Phygens利用GPT设置材料属性。
和之前的工作一样,先还是传统的输入多视图图片+colmap+恢复高斯,然后再是PGSR。 然后和Physdreamer不一样的是,Physdreamer只用了传统的SVD(图片生成视频),而这个模型多了个接口,还可以接(文+图)生视频等等各种生成模型。
其余处理和Physdreamer一样,就是用PhysGaussian的方式,给定初始条件然后进行仿真,再用SVD生成的视频作监督,只是这个监督是光流的监督 ,就是在像素级别上让模拟出的运动轨迹(Î_t)与目标运动轨迹(I_t)尽可能接近,使用光流的好处是在大尺度的运动范围下,光流的监督相比于结构损失更加稳定,且计算开销小很多,等这个代码开源了我想去测一下计算开销。具体来说可以看下面这个图,PhysGaussian在模拟飞机螺旋桨的时候,螺旋桨会出现不自然的变形,这是因为PhysGaussian没有优化物理参数,而这篇文章用了能量最小化的物理约束进行优化,这个图就正常了很多。

其次,Physdreamer只做了弹性情况的仿真,这个工作可以拓展到多种材料(一共七种:1弹性体: 杨氏模量𝐸和泊松比 𝜈;2塑性体: 𝐸,𝜈,屈服应力 𝜏 3金属: 𝐸,𝜈,屈服应力 𝜏;4泡沫: 𝐸,𝜈,塑性粘度 𝜂;5沙: 摩擦角 𝜃;6牛顿流体: 流体粘度 𝜇和体积模量 𝜅;7 非牛顿流体: 𝜇,𝜅,𝜏𝑌,η)。 因此他们大多数的数据都是和PACNerf作对比,但其实以上所有论文的仿真都是建立在胡渊鸣18年的那篇SIGGRAPH上的,理论上他们能做的场景physdreamer也能做,所以我觉得这个不能算是他们的创新点。
不过有个关键的点文中没提,Physdreamer最重要的一点是生成视频的真实度有限,所以他们只取了视频的前8帧作监督,但是这篇工作并没有讲他们生成了多少帧视频来产生光流作监督, 只是说明光流的效果产生的效果物理真实感更强。其次,大部分的论文都是从视觉的角度去分析的,目前还没有人对胡渊鸣的那个物理仿真的代码做过优化(确实真正的物理仿真需要较多的精力去钻研),如果考虑机器手的操作倒是有可能有优化的方向。
CVPR 2025 其余工作
这篇文章昨天刚开源,该工作(DGA)用于通用机器人灵巧抓取。由于灵巧手高自由度和物体形态多样性,生成高质量抓取姿态具有挑战性。DGA通过表面拉力、外部渗透排斥力、自碰撞排斥力三种物理约束,在训练和采样过程中提升抓取的稳定性和合理性。此外,引入大语言模型(LLM)增强物体表征,结合3D点云和文本语义,提高对目标物体的理解。然后还做了一个数据集。
这个工作提出了StoryEval,一个专为文本生成视频模型设计的评测基准,用于衡量模型在事件连贯性、长视频生成方面的呈现能力
3 LAYOUTVLM: Differentiable Optimization of 3D Layout via Vision-Language Models
本文提出LayoutVLM,一种基于视觉-语言模型(VLMs)的3D布局生成方法,能够将未标注的3D资产按照自然语言指令生成物理可行(避免碰撞、越界)且语义合理(符合指令)的场景布局。
4 Learning Physics From Video: Unsupervised Physical Parameter Estimation for Continuous Dynamical Systems
通过分析视频中的物理运动来估计连续动力系统的参数,无需手动标注数据,不同于以往基于视频帧预测的方法,这个方法用Encoder将视频帧映射到Latent Space,得到动力学变量z。只在潜在空间中优化,提高训练稳定性和效率。鲁棒性强,但是目前应该只能解ODE方程(普通的微分方程),不知道能不能推广至数值求解。
5 FluidNexus: 3D Fluid Reconstruction and Prediction from a Single Video
这个工作应该是Jiajun Wu 和Zhu Bo(我本科导师的导师,主要领域是图形学和物理仿真)合作的工作,做单视频3D流体重建、未来预测和交互模拟。比较有意思的点是,他们采用两层粒子表示,同时进行物理模拟和渲染:物理粒子:基于PBF模拟流体的速度场和密度场。视觉粒子:基于3D高斯建模流体的视觉外观,并随物理粒子流动。感觉这是一个不错的idea,因为我之前尝试过让粒子同时携带高斯和物理属性,但是效果一直不好,他们的工作思路算是解决了我之前的疑问吧。不过他们还是用的生成模型做预测,可见流场的物理属性恢复与仿真目前还是挺有难度的。
6 PhysAnimator: Physics-Guided Generative Cartoon Animation
蒋陈凡夫他们组的工作,将静态动漫图像转换为风格化动画。这个工作其实和去年那篇CVPR best paper挺像的,但是可以模拟多种物理属性的物体。

7 PhysVLM: Enabling Visual Language Models to Understand Robotic Physical Reachability
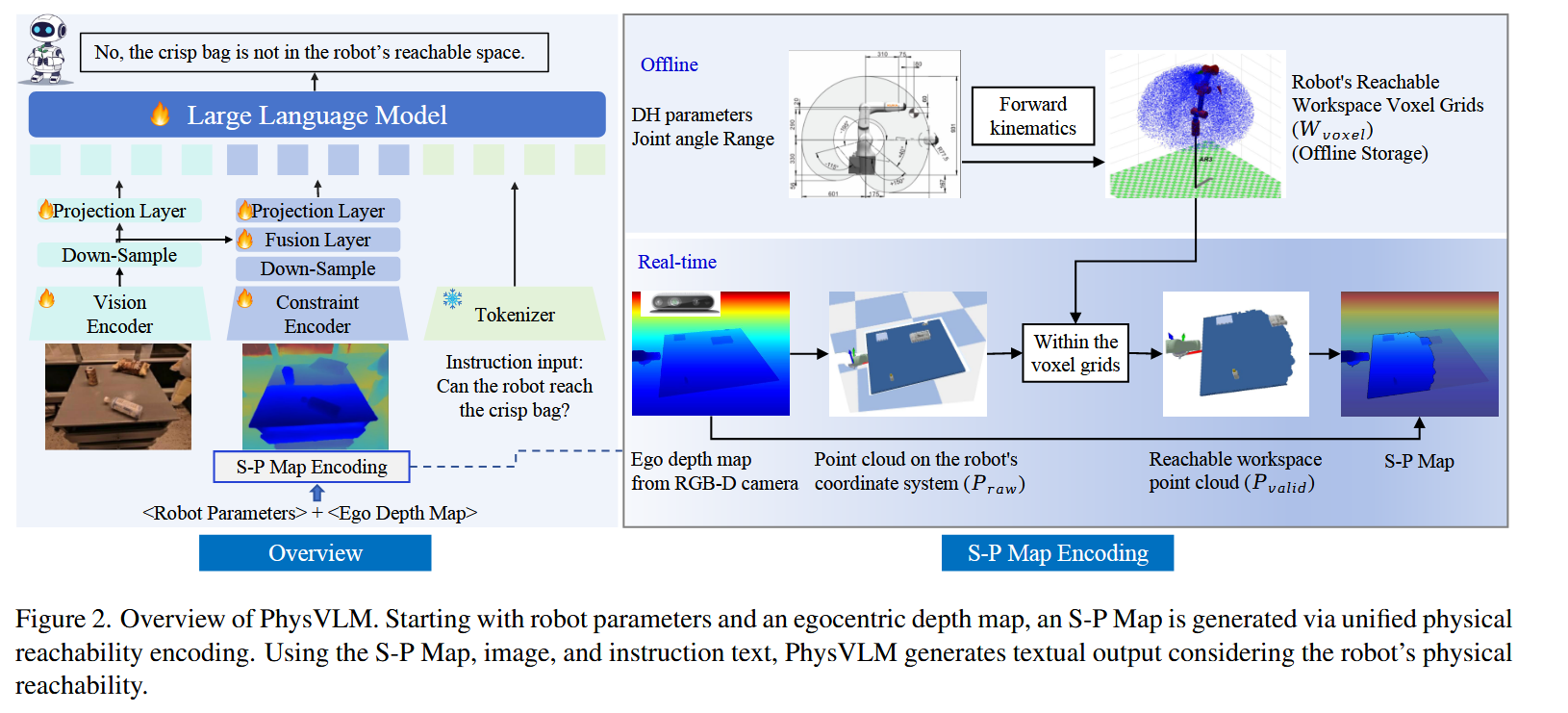
该研究提出了一种新型视觉语言模型(VLM)——PhysVLM,旨在提升机器人在执行任务时对自身物理可达性的理解能力。PhysVLM采用双分支架构,一部分用于视觉处理,另一部分用于处理S-P Map,并通过融合层将两者结合,以确保推理过程中既考虑视觉信息,又兼顾机器人物理约束。研究团队构建了一个大规模的多机器人数据集 Phys100K,并设计了 EQA-phys 基准测试来评估模型的性能。
具体来说,假设有一个机器人,它的任务是从桌子上拿起一个薯片袋,然后放到一个碗里。传统的视觉语言模型看到这个场景后,可能会直接生成指令:“拿起薯片袋,放入碗中。” 但问题是,它并不了解机器人本身的物理可达性,也就是说,它不会考虑机器人是否真的能伸手够到薯片袋。PhysVLM 的改进在于,它引入了S-P Map(空间物理可达性映射),可以帮助模型理解机器人真正能够触及的范围。当PhysVLM观察到这个场景时,它不会直接给出“拿起薯片袋”的指令,而是会先判断薯片袋是否在机器人的可达范围内。如果它发现薯片袋超出了机器人手臂的极限,它会先建议:“移动机器人靠近薯片袋。” 在移动完成后,它才会生成下一步指令:“现在可以拿起薯片袋,并放入碗中。”
感觉这个工作的思路挺清楚的,不过具体细节我还没看明白。框架如下:
8 Physics-Based Full-Body Human Reaching and Grasping from Walking Data
和上个工作有点像,这篇工作证明了简短的行走数据可用于生成多样化的抓取运动,有效降低数据采集成本,同时保证物理可行性和自然性,大致侧重于机器人的手脚协调、平衡调整。
9 PhysicsGen: Can Generative Models Learn from Images to Predict Complex Physical Relations?(http://www.physics-gen.org.)
和之前字节的那篇HOW FAR IS VIDEO GENERATION FROM WORLD MODEL: A PHYSICAL LAW PERSPECTIVE有点像,总而言之就是得出结论,目前的视频生成模型没有办法生成长时间的符合物理规律的视频,不过这篇工作的主要贡献点更多的是还是在数据集上吧。
新的idea
因为上述CVPR一篇都没开源,所以我正在跑一篇GIC的工作,这篇工作是Neurips 2024的oral。
GIC
论文题目:GIC: Gaussian-Informed Continuum for Physical Property Identification and Simulation
输入一组多视图的图片以及已知的相机内外参数,目标是恢复出用连续粒子表示的物体几何外形和物理参数,是前几篇工作的集大成者,主要的创新在于物体内部粒子的填充。我最近准备看看这篇文章的细节和代码部分。
整体框架如下:
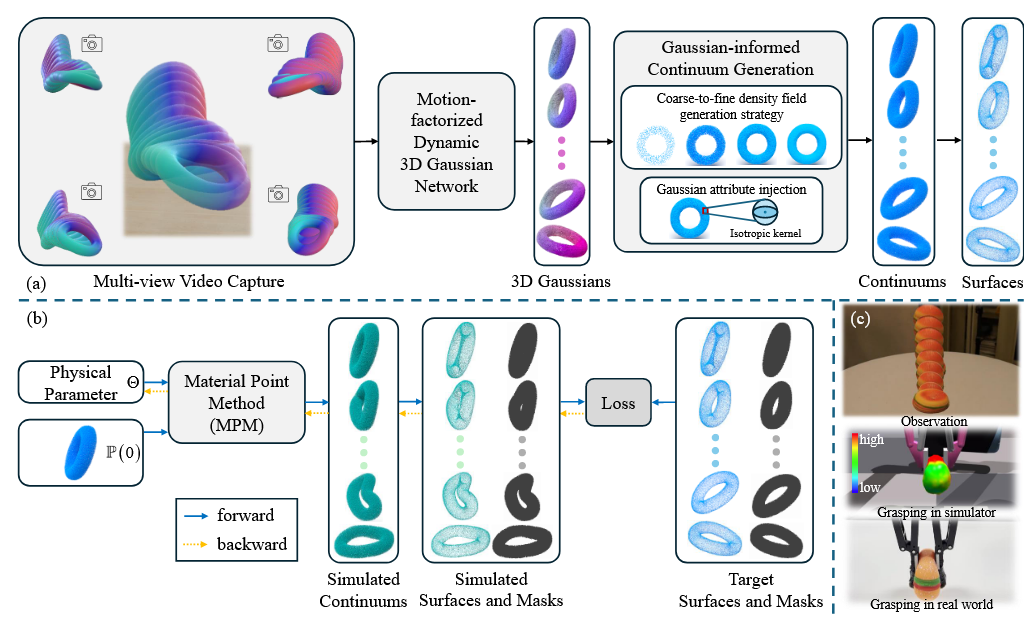
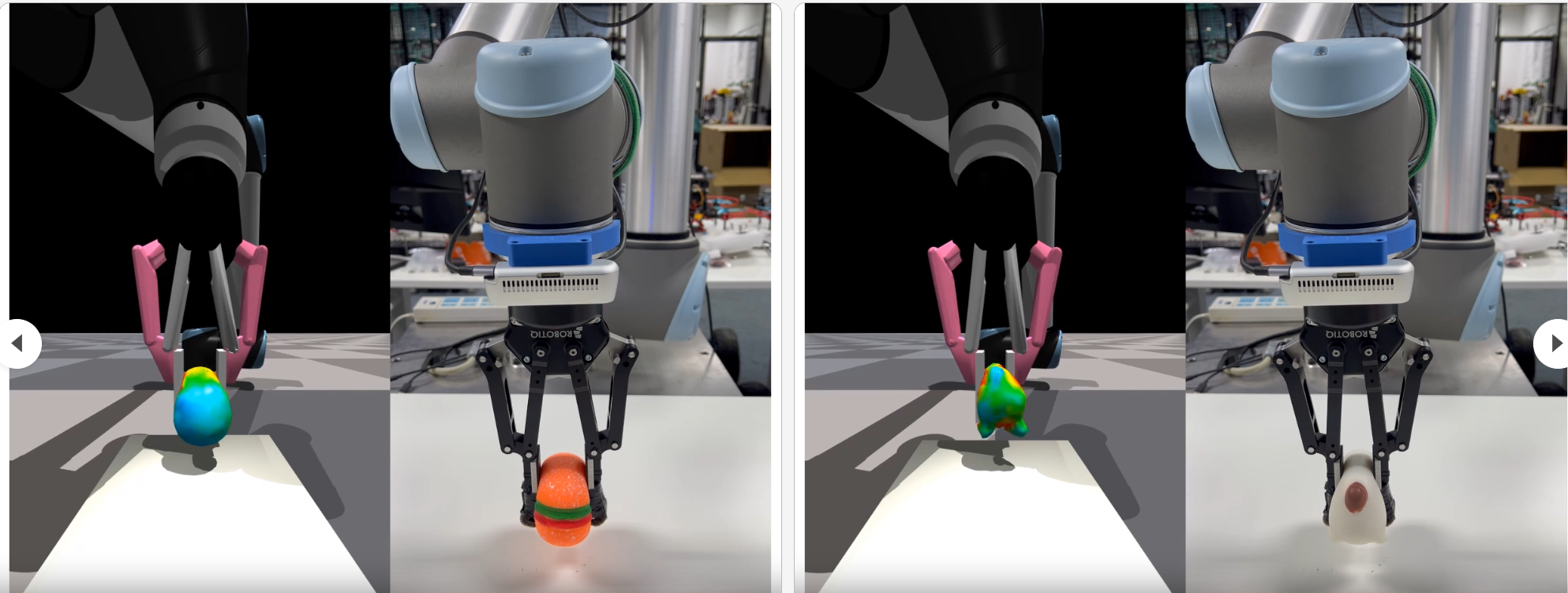
总体来说,他们已经实现了用机器手实现简单的操作并同时恢复出物理属性,那么我的想法很简单,考虑用灵巧手去抓这个柔性物体,并同时实现物体物理属性的估计。 技术难点如下:1 首先此前所有的工作都基本未考虑遮挡情况下的物理属性恢复,但是灵巧手操作的时候肯定有遮挡,所以在有遮挡条件下进行物理属性的估计会比较难,不过有遮挡情况下的人手+刚性物体的表面重建老师应该比较懂;2 灵巧手与柔性物体的接触面积远比GIC的工作大得多,我希望能够和DecoupledGaussian结合一下,最好能够把不同时刻下的灵巧手和柔性物体的几何变化图分离出来;3 手物分离后,就可以单独对物体进行仿真,再按照PACNerf那种方式恢复物理属性;4 有了物体的几何表面和物理属性后,是否可以调整关节的角度/手指的位置?比如找一个failure case,传统的灵巧手去抓一个橡皮泥,用力太大,则橡皮泥的几何发生明显的变形从指间滑落,用力太小抓不起来之类的,不过这方面我的了解还不是很深入;
反正我目前想先仔细地看看GIC的代码,然后把GIC作为baseline复现出来,再接到灵巧手上,先把硬件调通?然后不考虑强化学习、轨迹规划、触觉之类的,就先把物体放到灵巧手正下方,人工控制手执行抓取动作,做一个有遮挡条件下的物理属性恢复,或者直接用人手抓都行,不过我主要是想顺便趁这个机会学习下灵巧手硬件相关(ros)的东西所以有灵巧手更好;其余部分,比如怎么和VLA结合起来,怎么根据物体的属性调整手抓取的姿势和力之类的以后再说。
上次的讨论结果
上周老师让我去测一下Physdreamer的运行时间,根据作者所说,在NVIDIA V100 GPU 需要花费1分钟来推理生成1s(24帧)的预测视频。这个代码对显存要求比较高,我还没跑起来,所以我就推测了一下,因为推理包含三个部分,分别是生成8帧的视频(在我自己的设备上大概需要20s,在他们的V100上应该更快)+渲染损失+仿真,而仿真的过程根据PhysGaussian的结果已经能够达到15~20FPS,那么大部分的时间都是花费在这个不断渲染损失并优化物理属性场的过程上,推测是40s左右。
我找到了一篇文章 Simanything,里面有目前大部分文章的对比,结果如下:
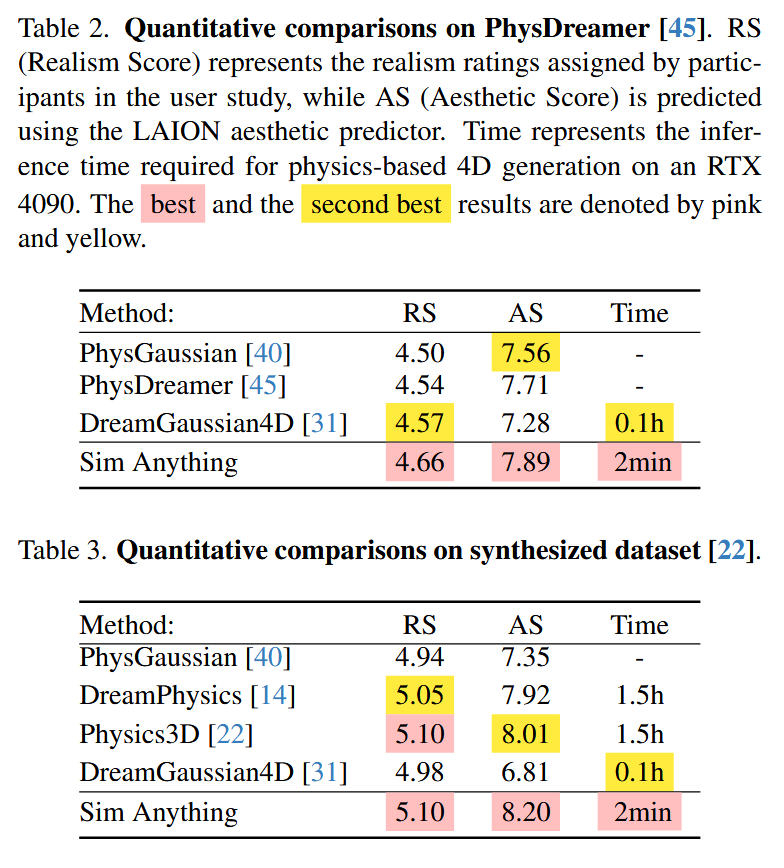
这个表格中PhysGaussian没有时间,是因为PhysGaussian是纯粹的仿真器,可以类比于神经网络的一次前向推理;而PhysDreamer没有时间,是因为他们认为训练SVD模型的时间很长,但PhysDreamer直接调用了已有的SVD模型,所以就没对比时间。
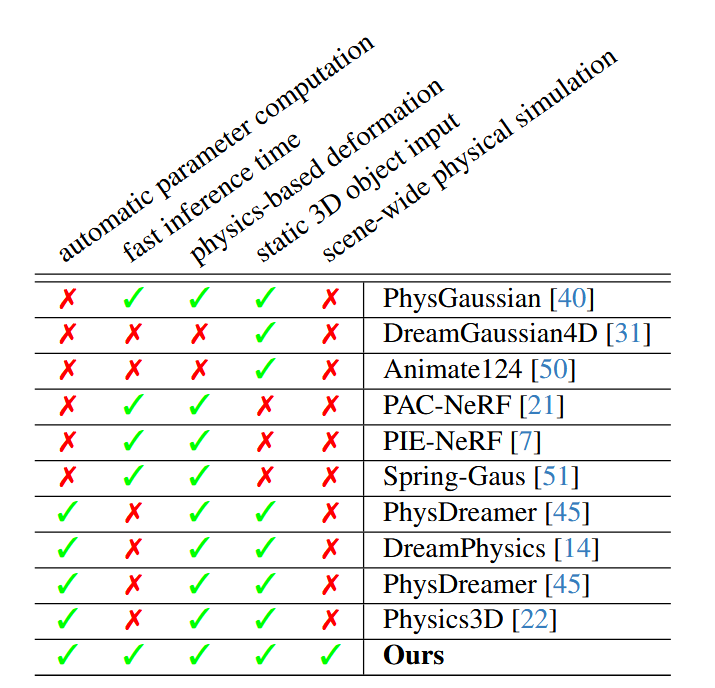
这是这篇文章中和以前工作的一些对比:
以及这篇工作的整体框架:
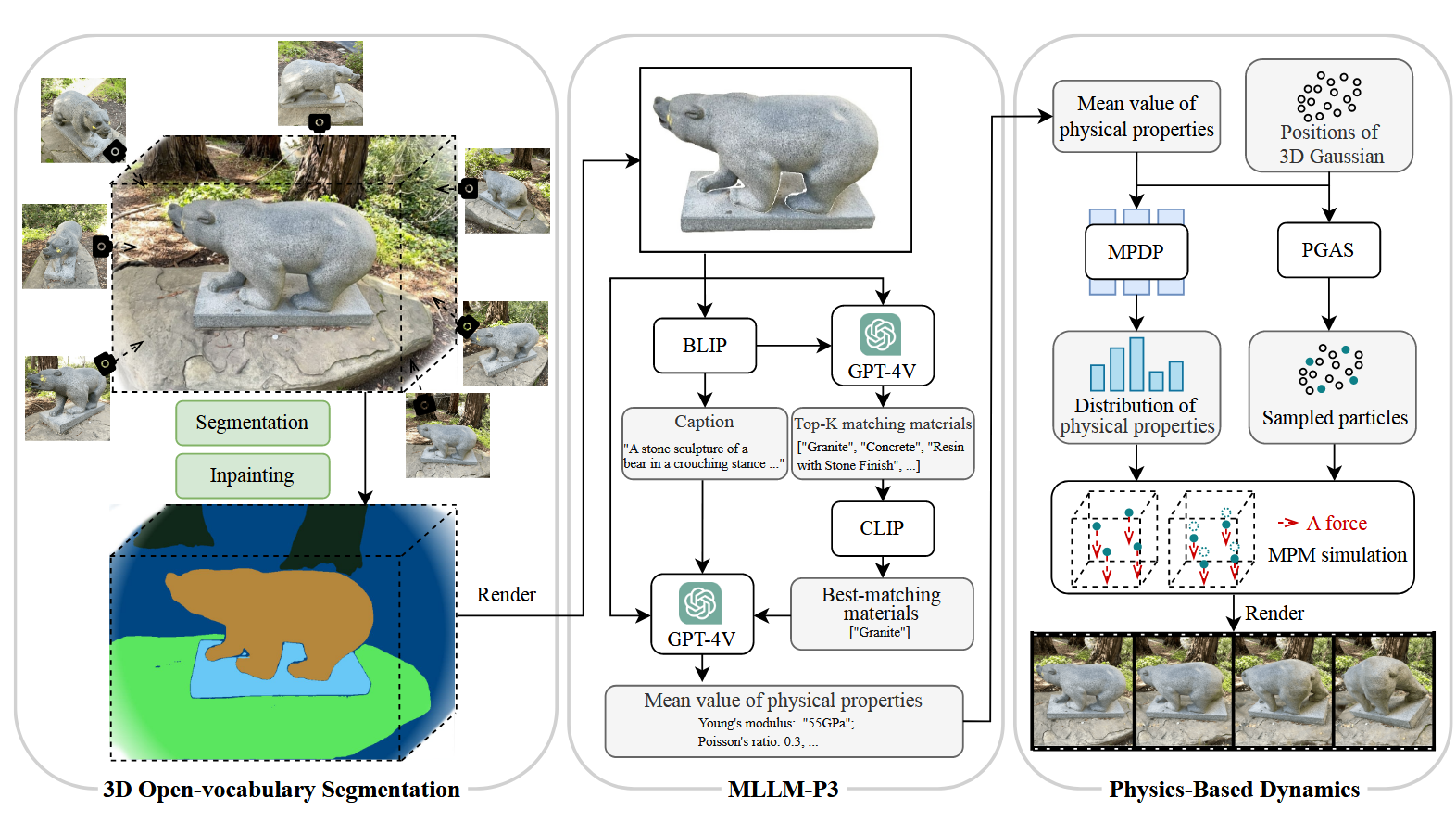
这篇文章和DecoupledGaussian、PhysFlow一样都是投今年CVPR的工作,但是Simanything这个工作没中,我个人感觉原因可能有以下两点:1、Simanything 的分割做的不够好,而且他们的demo和DecoupledGaussian的demo一模一样,最后的效果一对比就被比下去了;2、他们文章中写的创新点是加速,但是他们之所以能够加速,首先他们用的是真实世界的视频输入作为监督信号,天然就比用生成视频的方式快;其次,他们用GPT-4V先预测了一个物理属性的均值,再去优化物体各个地方相对于均值的偏差,但是GPT-4V的输入是视觉信息(图片)+ 语言描述(BLIP)+ 语义匹配(CLIP),那么如果一开始GPT预测的属性已经很准了(大部分物体的物理属性在空间中的变化还是比较均匀的,比如一个物体的头部和底部的密度一般不会相差太大),那么优化自然会快很多很多,这个感觉完全可以通过调参数调出来。所以综合来看这篇工作的创新性不够,所以没中也是合理的。
不过这篇文章可能用于参考的地方如下:
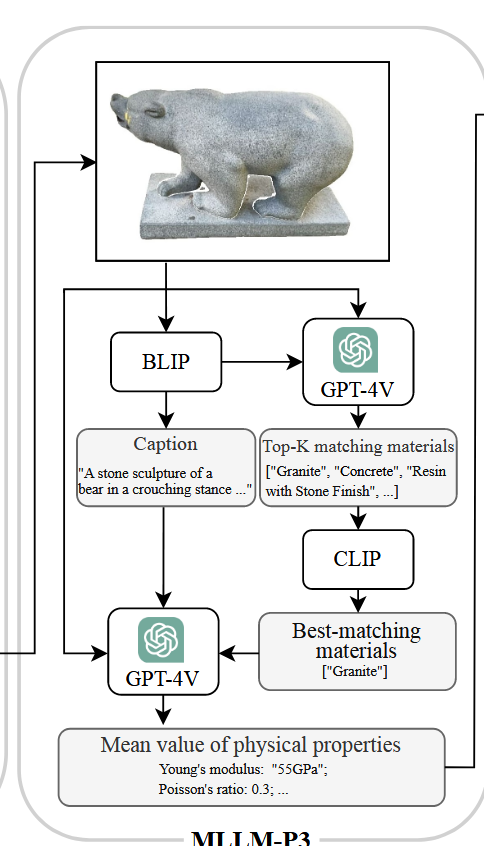
他们描述了一张图片,然后输出了TOP-K个最需要预测的物理属性;那么迁移到机器人上,这个之前和金柯师兄讨论过,是不是就可能和VLA结合起来,输入一个动作(文本描述)+视觉信息(图片),输出执行该动作可能需要预测的物理属性之类的?
之后准备做的工作
首先把GIC论文和代码的细节部分看完,等那些CVPR的工作的补充材料或者代码开源了之后我去仔细看看。
然后有一些挺有趣的工作我也准备去看看。