
实验部分
周三晚上和老师讨论的思路是让我找师兄讨论下手物分离,然后先从简单的平面仿真做起;
我回去想了想,换了个想法,因为既然最后物体的SDF场是由NeuralFeels给出的,那么我其实只需要验证下对软体物体仿真的部分就可以了,对3D表示的精确度没有要求。
那么现在的问题是从我拍的照片中恢复出物体的3d表示,所以我的想法是就用dino+sam+zeros123+InstantMesh恢复出一个3D物体的mesh表示,然后再做仿真就好了。
输入的原始图片如下:

然后使用dino,这个模型能够根据文字提示把图片中的内容圈出来
输入提示词 “a star” 过dino得到下面这个结果

这个模型会输出一个检测框(列表,每个元素是一个四维张量,分别是检测框的长宽和xy位置)以及文字+得分(如:a star (0.39))
可以看得出来这个dino模型可能会出现误判,反正我先不管了,就用得分高的那个检测目标和方框,经过SAM分割,输出结果如下:

然后用zeros123生成多视角的图片,输入是上面那个用SAM分割好的图片,输出结果如下:
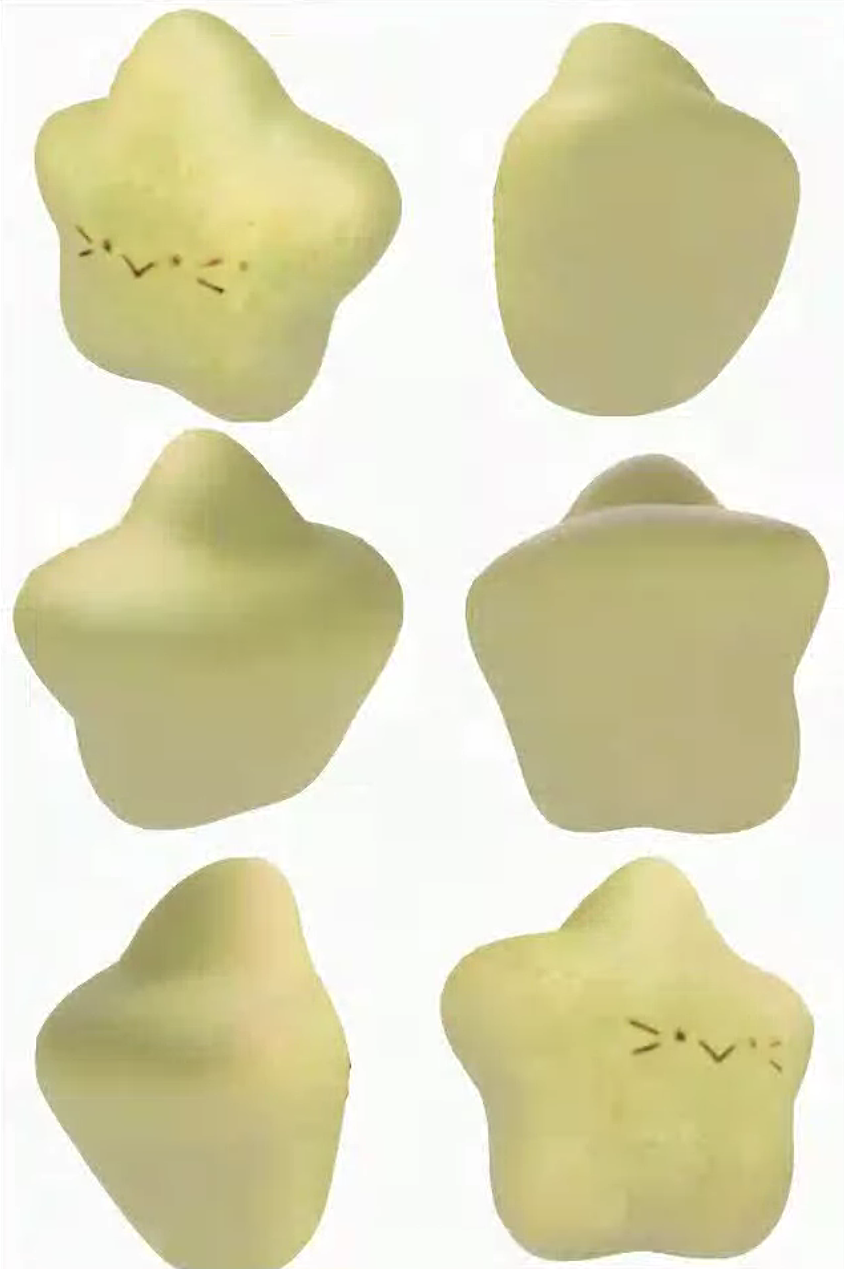
这之后我用InstantMesh重建了物体的mesh,结果如下
至此已经得到了物体的mesh了(虽然不太准)
然后我准备先整理下代码,继续在此基础上做我的仿真实验。
组合生成的调研
还有之前老师让我去调研的几个组合生成相关的工作,这几次组会都没来得及讲,所以我就简单介绍下
Two by Two
题目 :Two by Two : Learning Multi-Task Pairwise Objects Assembly for Generalizable Robot Manipulation
CVPR2025 04.06 网页
总结: 输入两个需要装配的物体,比如插座和插头,这个工作是一个数据集,然后训练了一个网络,能够把两个物体的点云对齐,比如把插头和插座对准。
以下是细节:
让机器人成功完成装配之类的任务需要对对象对之间的空间关系进行精确推理。机器人需要准确估计每个物体的 6D 姿态,包括它们在空间中的方向和位置。 所以这篇论文的主要创新之处就在于考虑了物体之间的空间关系吧。
2BY2数据集: 规模与多样性:第一个大型组装数据集,包含517对物体、1034个实例,覆盖18个细粒度任务(如插头插入、鲜花插瓶、面包放入烤面包机等)。
标注信息:提供6D姿态(平移+旋转)和对称性标注,模拟真实场景中的物理约束。
任务分类:分为三大类(Lid Covering, Inserting and High Precision Placing),每类进一步细分为具体任务(如钥匙开锁、硬币存钱罐)。
工作流
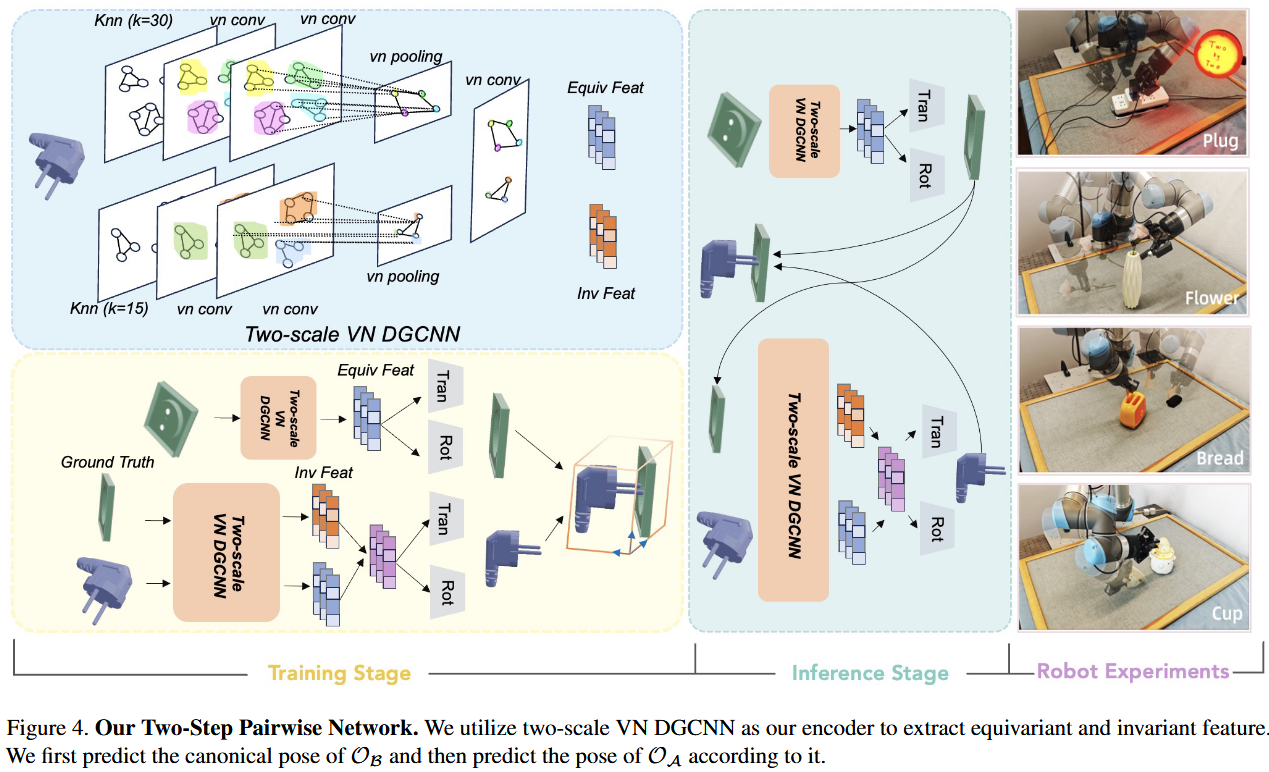
具体实现方法
解决的问题是日常成对物体组装任务中的6D姿态估计问题,即在三维空间中对两个物体进行精确的相对位姿(位置+旋转)预测,使其能够完成功能性组装(如插头插入插座、盖子盖在瓶子上等)。
先对之前的数据集作了一个处理,分成两部分,物体 B 是底座或接收组件,例如螺母、花瓶、邮筒。物体 A 是配件组件,例如螺栓、花朵、邮件。
输入:
两个物体的点云 $P_{A}$ 插入物体,如插头)和$P_{A}$(基础物体,如插座),每个点云为1024个点的坐标集合。
输出:
两个SE(3)变换矩阵 ($T_{B}, R_{B}$) 和 ($T_{A}, R_{A}$),然后分别将$P_{A}$和$P_{B}$变换到预定义的Canonical Space,使其在规范空间内完成正确组装。
规范空间:根据任务类型定义的基础坐标系。例如: 放置类任务(如花瓶):物体稳定放置在XY平面,Z轴垂直向上。 插入类任务(如插座):基础物体固定在XZ平面(模拟墙面),插入方向沿Y轴
方法:
网络分为两个分支,模仿人类分步组装逻辑(如先固定插座,再插入插头)
Branch B(基础物体预测)
两尺度Vector Neuron DGCNN:提取$SE(3)$等变特征(旋转/平移时特征同步变换)。
MLP预测头:从特征中直接预测旋转矩阵$R_B$和平移向量$T_B$
Branch A
基于Object B的预测位姿,预测Object A(如插头)的位姿
将Object B的SO(3)不变特征(与旋转无关)与Object A的SE(3)等变特征点乘融合,保留几何对齐信息。
MLP预测头:输出$R_A$和$T_A$
训练策略
分步独立训练
Branch B训练:使用Object B的规范位姿真值(无需考虑Object A)。
Branch A训练:固定Branch B,使用Object B的真值位姿(避免预测误差传递)。
推理阶段:先预测Object B位姿,再基于此预测Object A位姿。
loss 分两个,一个是平移loss,$\mathcal{L}_{\mathrm{trans}}=\|T_{\mathrm{pred}}-T_{\mathrm{gt}}\|_1$,另一个是旋转loss,$\mathcal{L}_{\mathrm{rot}}=\arccos\left(\frac{\mathrm{tr}(R_{\mathrm{gt}}R_{\mathrm{pred}}^T)-1}{2}\right)$
跨物体特征融合:通过点乘显式建模功能关系(如孔-轴匹配)
Infinite Mobility
总结: 定死URDF的文件框架,在此基础上生成各种各样零件的排列方式,从而得到铰接的物体。
以下是细节部分:
这篇文章要解决的问题是如何高效地生成大规模高质量的关节物体,以满足具身AI相关任务的需求。现有的方法要么是基于数据驱动的,要么是基于模拟的,这两种方法都受到训练数据规模和质量或模拟的真实性和劳动强度的限制。
核心原理
我觉得这篇文章的一个比较好的思路是: 每个刚体都描述为一个链接,每个关节是两个链接之间的连接。通过这种结构,铰接对象可以描述为树状结构,其中每个节点代表一个链接,每条边代表一个关节。 从根节点开始,通过语义规则递归添加子节点,生成必要部件(比如椅子的轮子等),同时允许多样化扩展。
部分URDF截图:
定义物体:

生成物体之间的连接:
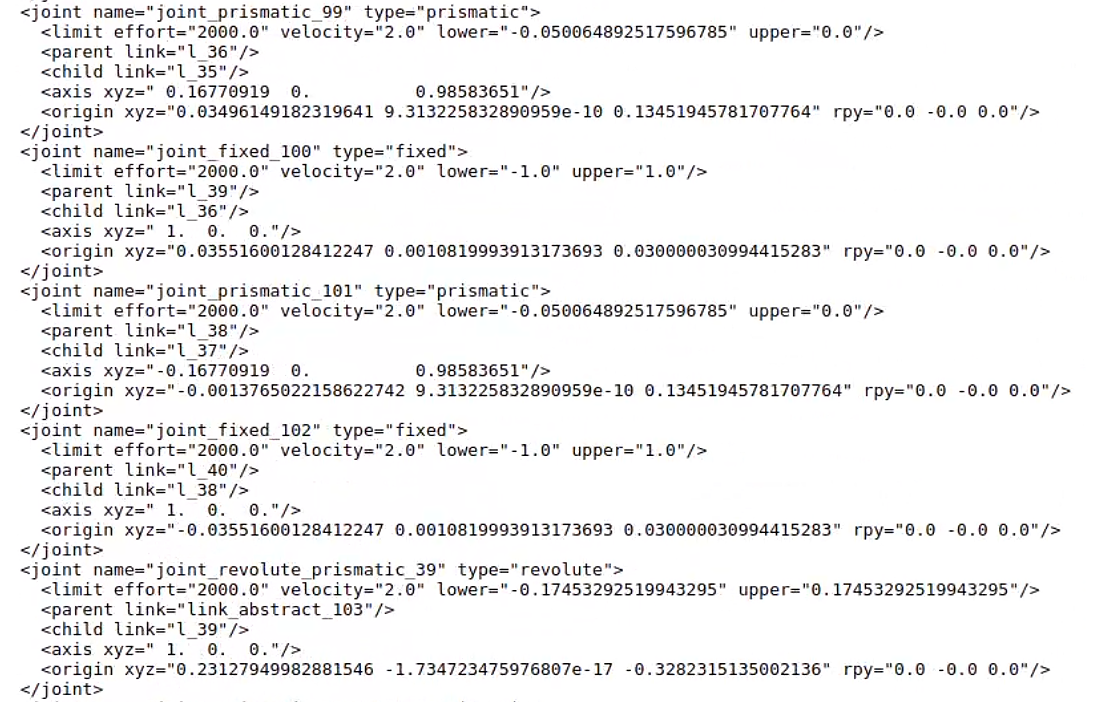
部分物理属性(如摩擦、阻尼)尚未自动化生成,而且底层的组件部分还是有限的(blender api + 本地库),并非生成得到,但是这个用trellis3D之类的会非常好生成,因为只需要mesh和mtl了
结果

不过对于lay out布局来说,目前还是手动指定的,比如下图就是作者在论文中给出的

但是据作者所说,他们应该准备做生成物体布局的工作了,估计今年下半年能够做出来
还有一个缺点是这篇论文生成的物体可能不能拆卸或组装
PartRM
PartRM: Modeling Part-Level Dynamics with Large Cross-State Reconstruction Model
CVPR2025 03.19 网页
总结: 也是3D铰接物体的生成,区别是之前的工作更加侧重于生成 大量的铰接物体以供训练,这个工作侧重于从一张图片中推理出铰接物体的未来运动(比如给一个关闭的门,能预测出门打开的样子),代码我还没来得及看
以下是具体细节:
问题
 这篇论文主要的工作集中于部件级动态建模方面
这篇论文主要的工作集中于部件级动态建模方面
1 提高了动态建模的精度和一致性:现有方法如Puppet-Master和DragAPart通常只能处理单视图图像或视频。而PartRM能够生成3D-aware的部件级运动,并且在多视角下保持一致性 ;也就是说之前的工作都是在平面上的抽屉开合,这个工作有物体的三维表示(高斯)
2 PartRM提出了PartDrag-4D数据集,该数据集提供了20,000多个部件状态的多视角图像,极大地丰富了训练数据。
3 PartRM采用了两阶段训练策略,分别处理运动学习和外观/几何学习,避免了灾难性遗忘,从而提高了模型的泛化能力。不过我感觉这个两阶段训练处处都有,不能算创新?
输入&输出
Pipeline
任务定义如下: 给定单张铰链物体的图像,一张静态的物体图像(例如微波炉的正面图) $o_t$ 和用户指定的拖拽 $a_t$(表示部件的运动方向和幅度,一个视图,像素坐标级别移动)(这个$a_t$表示从门关闭的位置到门打开的位置的运动)
输出t+N时刻(N任意) PartRM会输出门在整个过程中从关闭到打开的每个时刻的运动信息。例如,它会给出门的具体位置,门的移动幅度,以及在不同时间点的姿态,而且由于是高斯渲染,所以能保证多视角的一致性。
输入:一张包含物体(如门)的单视图图像,以及门的起始位置和终点位置的拖拽交互信息(这些位置是通过像素坐标指定的)。
输出:模型生成物体的3D表示,以及在不同时间点和视角下的物体状态和运动轨迹。
工作流
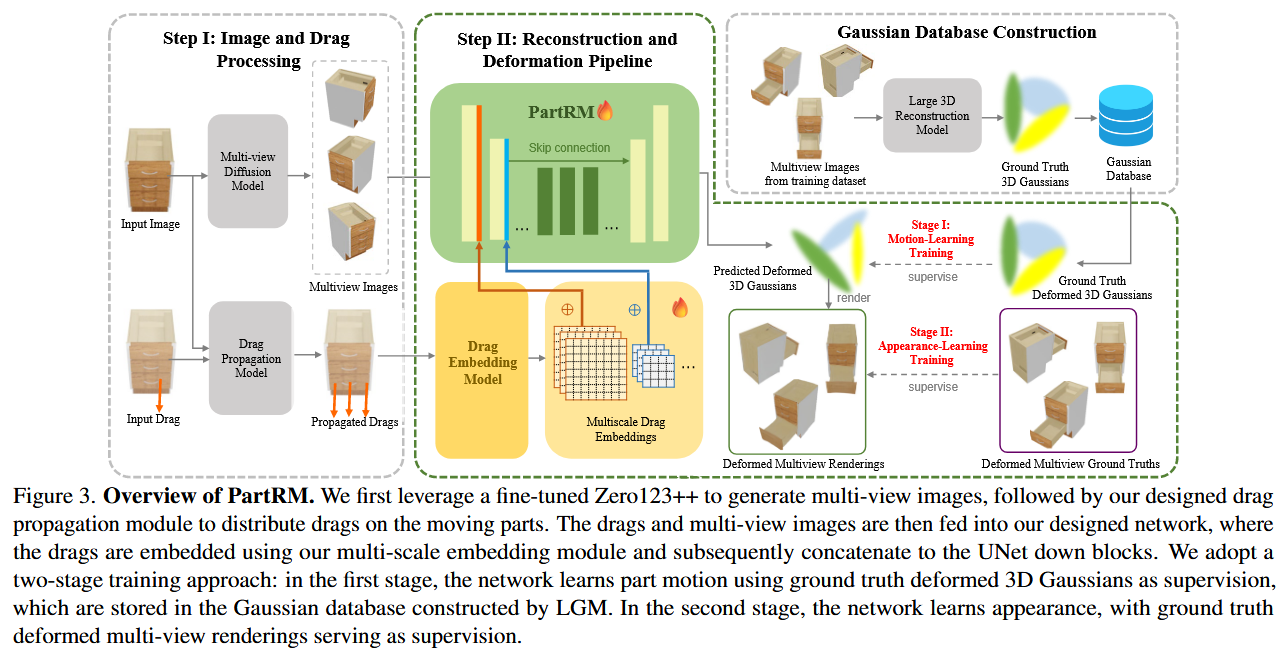
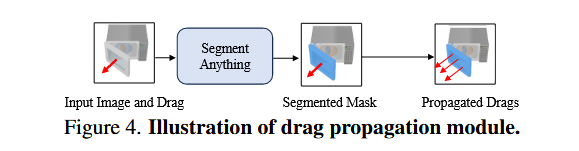
首先会利用 Zero123++ 生成输入的多视角图像,然后对输入的拖拽在用户希望移动的 Part 上进行传播。
这个part是利用SAM分割得到的
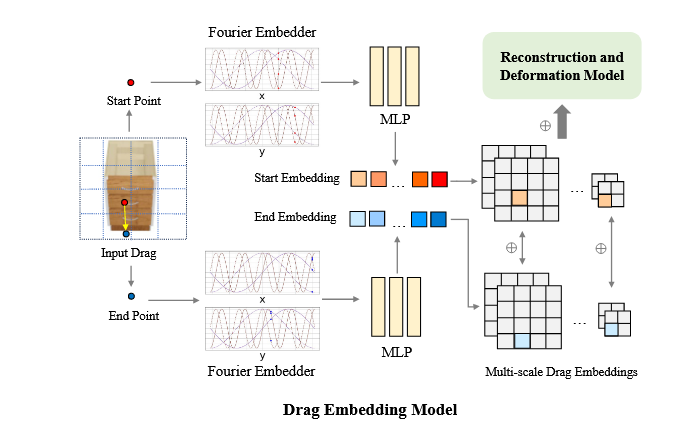
这些多视角的图像和传播后的拖拽会输入网络中,这个网络会对输入的拖拽进行多尺度的嵌入,然后将得到的嵌入拼接到重建网络的下采样层中。
因为网络可能不一定能识别到拖拽的区域。因此对拖拽进行传播到需要被拖拽部分的各个区域,使得后续网络感知到需要被拖拽的区域,为此我们设计了一个拖拽传播策略。如图所示,我们首先拿用户给定的拖拽的起始点输入进 Segment Anything 模型中得到对应的被拖拽区域的掩码,然后在这个掩码区域内采样一些点作为被传播拖拽的起始点,这些被传播的拖拽的强度和用户给定的拖拽的强度一样。
嵌入的过程如下:
在训练过程中,采用两阶段训练方法,第一阶段学习 Part 的运动,利用高斯库里的 3D 高斯进行监督,第二阶段学习外观,利用数据集里的多视角图像进行监督。
数据集
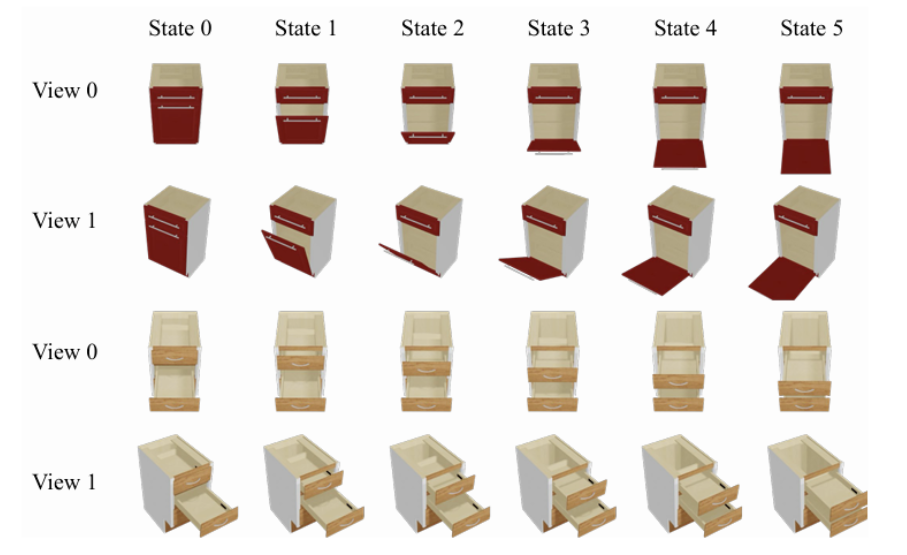
文中选取了 8 种铰链物体(其中 7 种用于训练, 1 种用于测试),共 738 个 mesh。对于每个 mesh,如上图所示,文中使其中某个部件在两种极限状态(如完全闭合到完全开启)间运动至 6 个状态,同时将其他部分状态 设置为随机,从而产生共 20548 个状态,其中 20057 个用于训练,491 个用于测试。为渲染多视角图像,我们利用 Blender 为每个 mesh 渲染了 12 个视角的图像。对于两个状态之间拖拽数据的采样,我们在铰链物体运动部件的 Mesh 表面选取采样点,并将两个状态中对应的采样点投影至 2D 图像空间,即可获得对应的拖拽数据。
泛化到未知的数据

因为只指定了物体运动的启动和终点,所以在比较平滑的运动上能够取得比较好的效果,但是应该也不会太好。
还有一个比较严重的问题,就是他们训练的时候是给了blender中的模型,比如一个抽屉,那么是可以学习抽屉从关闭到打开的过程的,因为模型见过抽屉里的东西,但是泛化到未知环境的时候,怎么生成那些没见过的视图的细节呢?
而且文中只提到了一点点应用于操作上的内容,不过我没明白这种生成方式是怎么应用上去的,理论上机器人不可能和高斯交互吧,可能要具体看看代码才知道。
CAST
CAST: Component-Aligned 3D Scene Reconstruction from an RGB Image
从单张RGB图像重建高质量3D场景,核心是通过分解场景为独立物体生成,并结合根据关系图定义的接触和支撑约束,利用SDF优化物体姿态,消除穿透和漂浮现象,确保场景物理合理性,实现高保真和物理合理的重建
虽然代码没有开源,但是这个工作是我目前见过的看起来效果最好的场景重建,论文的细节我准备下周花点时间去看看。
其重建出的3D场景的结果如下:
