论文信息
信息概览
Science Robotic 2019
论文题目: See, feel, act: Hierarchical learning for complex manipulation skills with multisensory fusion
论文单位: MIT
是否开源: 否
总结:
文章要解决的一个核心问题是机器人如何像人类一样,结合视觉和触觉信息,高效学习复杂的物理操作技能,比如玩 Jenga(叠叠乐)?
论文细节
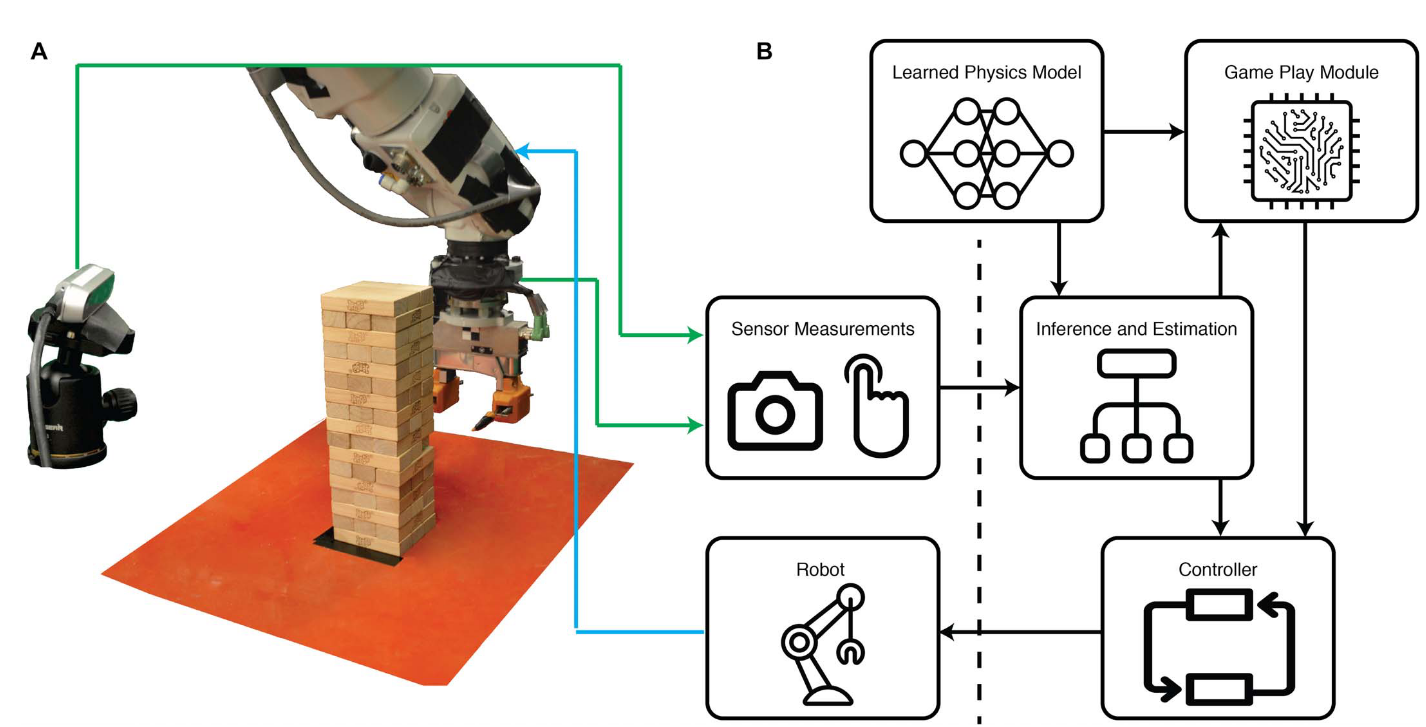
分析: 这个问题可以从两个角度来解读:1 机器人需要边操作边感知,用触觉和视觉来推测积木状态,而不是仅靠视觉;2 机器人需要同时处理可移动和不可移动的积木,制定合适的策略来提取积木,而不让塔倒塌。传统机器人学习主要依赖视觉数据,缺乏触觉推理能力,导致它们需要大量数据才能学会基本操作。而基于强化学习方法需要大量训练数据,但由于Jenga游戏中的物理交互细节微妙,RL难以快速收敛。因此,文中给出的方法可以按照探索(Exploration)+ 学习(Learning)+ 决策(Decision Making)的框架来解决。
探索
机器人随机选择一个积木并执行推的动作,并记录:积木的受力情况(触觉传感器),积木移动的位置和角度(摄像头),机器人末端执行器的参数(本体感知),塔的稳定性(由视觉观测),类似于人类玩Jenga时会试探性地推一下积木,看看它是否松动
训练
论文提出了一种分层学习(hierarchical learning)方法;
低层级:学习物理参数(如积木的受力情况、摩擦力、位移)
高层级:归纳行为模式(如“积木可以移动” vs “积木被卡住”)
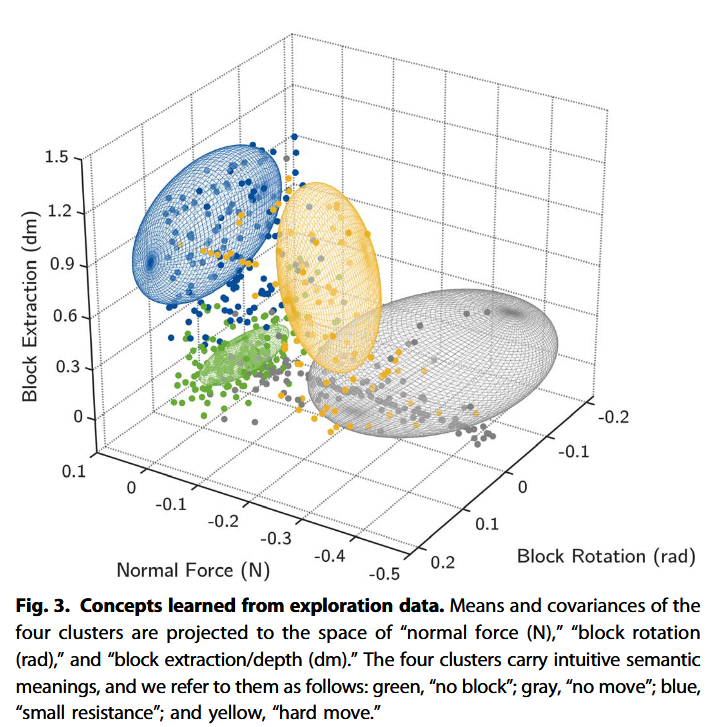
绿色集群表示机器人未与任何块接触的轨迹,特别是在轨迹开始时,测得的力可以忽略不计,并且块不会移动。灰色簇表示抵抗运动并被卡住的块,表现出较大的阻力并且几乎没有平移。蓝色簇表示相当容易移动的块(大位移)并且表现出可以忽略不计的阻力。黄色集群表示移动但对机器人提供有意义阻力的块。
计算:积木是否容易被推动(基于力反馈)/积木是否松动(基于历史数据)/积木移动时的可能路径(基于视觉+力传感器)
论文使用了贝叶斯神经网络(BNN, Bayesian Neural Network) 学习积木的力学行为模式,使机器人可以从少量数据中泛化:输入:推积木时的力+位移信息。输出:预测未来的受力情况和积木的运动轨迹。
泛化
机器人在每次推积木时,会先计算成功的概率。例如,如果积木之前被推过但没有动,机器人会降低推的力度或改变推的方向。
然后执行贝叶斯更新(Bayesian Update):机器人会随着每次操作更新对积木状态的信心。
例如:机器人发现某个积木很难移动 → 更新其状态为“卡住”,减少未来的尝试。发现某个积木容易移动 → 优先尝试此类积木。
更多训练的细节: 1 采用贝叶斯建模学习积木的物理属性; 2 用深度学习训练一个预测模型(输入力,预测积木的反应); 3 机器人自监督学习,不断改进对积木状态的推测;
思考
这个训练的框架也许有用,但应该仅限于摩擦力的框架,而且我对BNN并不太了解;
估计摩擦力的框架到时可以借鉴?即输入物体的rgb图+末端执行器的位姿+施加力的大小和方向,然后先算一步先验(即初步估计的摩擦系数,就能简单的判断这个力是否能推动物体)再输入神经网络,得到物体下一时刻的位移。
其他
论文提出了一种分层学习(hierarchical learning)方法,通过视觉和触觉融合,使机器人学习Jenga游戏中的操作技能
论文想要解决的问题是主动感知与混合行为。
首先是如何通过视觉信息和触觉信息来感知世界; 然后是如何通过多模态信息来学习操作;
基于RL构建的大部分方法都无法有效地利用利用有关对象和动作的物理知识,而且这些系统需要比人类多得多的训练数据来学习新模型或新任务,而且它们的泛化范围要小得多,鲁棒性也要差得多。
给机器人的任务是玩Jenga这个游戏。
对于这个任务,人类通过触摸积木并结合触觉和视觉感官来推断它们的交互来获取信息
基于此,机器人通过视觉信息来学习有关塔的位置和当前区块排列的信息。
以抽取的木条的数量作为评价指标;
机器人知道每一个时间步下的机械手的位姿,物体的姿势和施加到物体上的力
很多仿真系统中对于摩擦力的建模是很粗糙的,因此仿真到现实的gap是难以弥合的。
触觉信息是间断的,很难与视觉信息对齐。在Jenga任务中,视觉信息和触觉信息互相补充。
触觉反馈可以提供高分辨率的局部信息,以补充来自视觉的全局但粗略的信息。