论文信息
信息概览
CVPR 2025
论文题目: Structured 3D Latents for Scalable and Versatile 3D Generation
论文单位: THU
是否开源: 是
总结: 输入文本或图像,输出3D模型,并且有灵活的输出格式选择和本地 3D 编辑功能。
论文细节
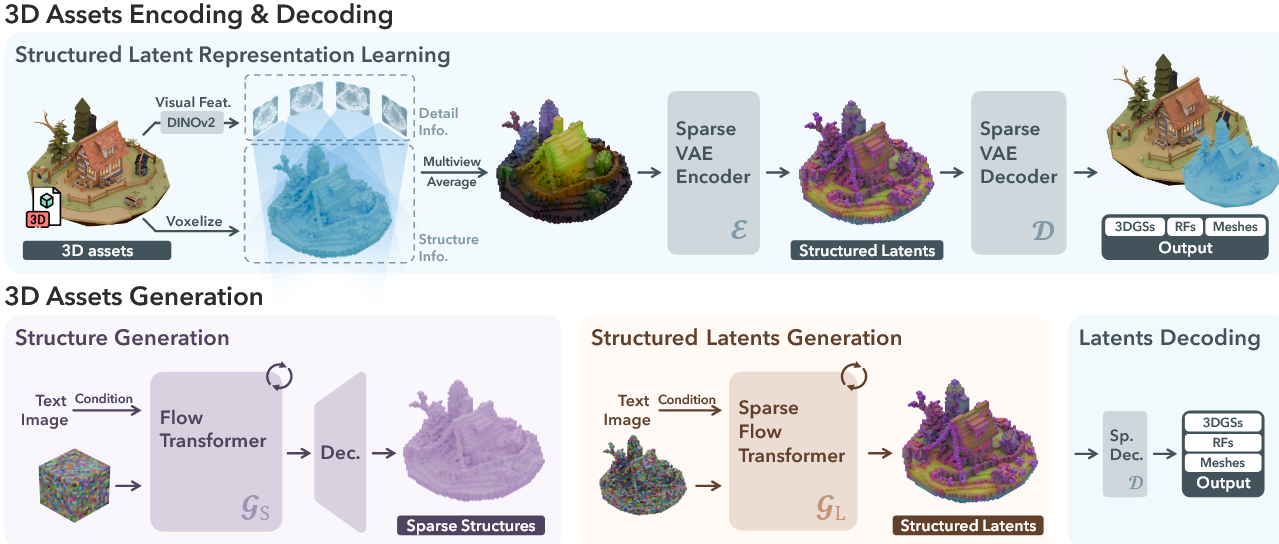
结构化潜在表示(SLAT)
SLAT 的核心思想是将3D资产的几何和外观信息编码为一个稀疏的3D网格 + 密集视觉特征的联合表示。具体设计如下:
稀疏3D网格结构
定义:对3D资产$\mathcal{O}$,定义一个分辨率为$N^3$(默认 $N=64$)的网格,仅标记与物体表面相交的“活跃体素”(active voxels),形成稀疏结构$\{\bm{p}_i\}_{i=1}^L$($L \ll N^3$)。

优势:稀疏性支持高效高分辨率建模,同时保留局部性(便于后续编辑)。
局部潜在向量
每个活跃体素 $p_i$ 关联一个局部潜在向量 $z_i ∈ R^C$,用于编码该区域的几何和外观细节。
特征来源:通过多视角渲染(150张随机视角图像),用预训练的 DINOv2 提取视觉特征,投影到体素并平均聚合,得到初始特征$ f_i$,再通过稀疏VAE编码为 $z_i$。

编码与解码流程
编码过程
视觉特征聚合
- 渲染多视角图像 → DINOv2 提取特征 → 投影到 3D 网格,生成稀疏特征 $f = {(f_i, p_i)}$。
稀疏VAE编码
- 使用基于 Transformer 的编码器 E,将 f 映射为结构化潜在空间变量 $z = {(z_i, p_i)}$。同时,输入的特征还会根据p加上一个正弦位置编码并进行序列化以便于输入到 网络中处理。
关键模块
- 3D Shifted Window Attention(Swin Transformer 这块我还没看懂),在稀疏体素间高效传递局部信息。
多格式解码
SLAT 支持通过不同解码器生成多种 3D 表示:
3D高斯(DGS)
- 每个 $z_i$ 解码为 $K=32$ 个高斯球(位置、颜色、透明度等),通过体积渲染损失$(L1 + SSIM + LPIPS)$训练。

辐射场(DRF)
- 解码为局部辐射体积(CP分解形式),用类似损失优化。

网格(DM)
- 通过稀疏卷积上采样到 $256^3$,用 FlexiCubes 提取网格,基于深度/法线图损失训练。

训练策略
- 先以 3D 高斯为目标训练 VAE,再固定编码器,单独训练其他解码器。
两阶段生成模型
稀疏结构生成
目标:生成3D资产的稀疏体素结构 $\{\bm{p}_i\}_{i=1}^L$
输入:文本(CLIP特征)或图像(DINOv2特征)。
模型:修正流变换器 $G_S$,生成低分辨率($16^3$)的稠密特征网格$S$,解码为二值活跃体素网格$O$。
先把随机初始化的稠密特征网络与位置编码并在一起,然后通过3D卷积VAE压缩为低分辨率特征$\boldsymbol{S}\in\mathbb{R}^{16\times16\times16\times8}$,在这个latent空间中去噪,条件是输入的文本或图片,之后将生成的 S 解码为稠密二值网格$\boldsymbol{O}\in\{0,1\}^{64\times64\times64}$,再转换为稀疏活跃体素 $\{p_i\}$。
关键设计
-
使用 Conditional Flow Matching (CFM) 目标,优化噪声到数据的向量场。 $\mathcal{L}_{CFM}(\theta)=\mathbb{E}_{t,\boldsymbol{x}_0,\boldsymbol{\epsilon}}\|\boldsymbol{v}_{\boldsymbol{\theta}}(\boldsymbol{x},t)-(\boldsymbol{\epsilon}-\boldsymbol{x}_0)\|_2^2.$
-
引入 logit-Normal(1,1) 时间步采样,提升稳定性。
局部潜在生成
输入:上一步的稀疏结构 ${p_i}$ + 条件提示。
目标:为稀疏结构 $\{\boldsymbol{p}_i\}$ 生成局部潜在向量 $\{\boldsymbol{z}_i\}$
模型:稀疏变换器 $G_L$,直接生成潜在向量 ${z_i}$。
稀疏卷积下采样
- 将 64³ 体素打包为更短序列,提升效率。
跨注意力注入条件
- 文本/图像特征作为 Key-Value。
局部编辑能力
SLAT 的稀疏性和局部性天然支持灵活编辑:
细节变体生成
- 固定稀疏结构,仅重新生成 ${z_i}$(通过新文本提示引导)。
区域特定编辑
-
指定编辑区域的边界框,结合 Repaint 策略:
- 第一阶段:仅生成框内新结构。
- 第二阶段:生成框内细节,保持框外内容不变。
网络模型架构
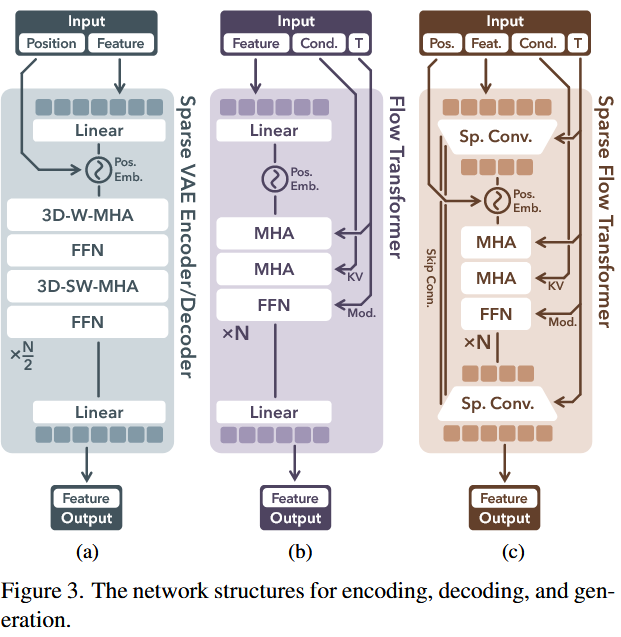
3D-W-MHA: 3D窗口注意力机制 FFN:指任何前馈型的神经网络,可以有多个层,也可以没有隐藏层 MLP:是一种特定的 FFN,通常具有至少一层隐藏层,并且每层之间是全连接的
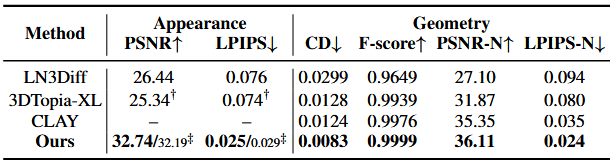
论文结果
该方法与其他方法的对比
重建质量的对比
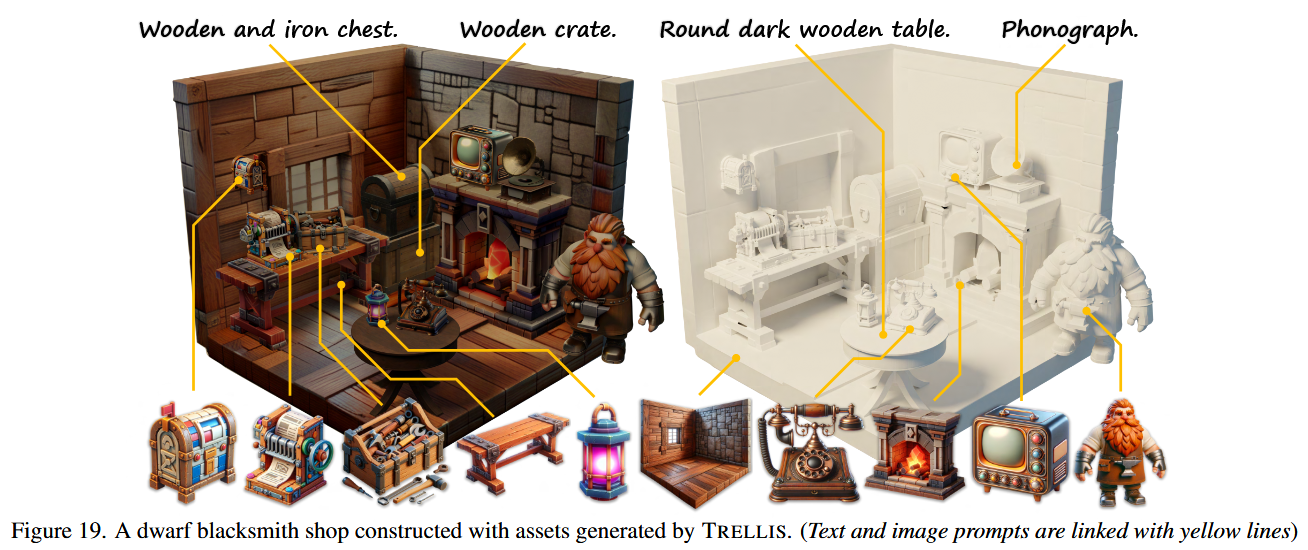
可视化结果对比

更加细节的结果